Pythonを用いた分散分析(ANOVA)あれこれ(2)
間が空いてしまいましたが(1)の続きとなります。こちらでは対応のある一元配置分散分析や、二元配置分散分析について纏めます。個人的な備忘録の色合いが強く、色々と端折っている部分があります。
※環境はJupyter Notebookの想定です。
※有意水準は全て5%(0.05)とします。
対応のある一元配置分散分析
使用するデータ
ここでは入門-統計学-第2版-という教科書171ページにある、対応のある一元配置分散分析の例題について、Pythonでトライしてみます。
こちらは2名の喫煙者Aさん、Bさんに対して、禁煙外来のカウンセリングが喫煙本数を変化させたかを検証する、という例題であり、以下の表がその結果となります。表内の数値は1日あたりの喫煙本数であり、水準1が相談前、水準2がカウンセリング1回目、水準3が2回目となります。
| 水準1 | 水準2 | 水準3 | 被験者平均 | |
|---|---|---|---|---|
| Aさん | 22 | 14 | 9 | 15 |
| Bさん | 14 | 8 | 5 | 9 |
| 群平均 | 18 | 11 | 7 | 12 |
statsmodelsを用いる方法
この例では同一の被験者に対する繰り返しの評価となるため対応関係が生じます。そのため被験者間変動(個人差による変動)を分離することが出来ます。実際にやってみるために、まずは表のデータフレームを作成します。
import numpy as np import pandas as pd from scipy import stats person = pd.Series(['A', 'B']) l1 = pd.Series([22, 14]) #水準1 l2 = pd.Series([14, 8]) #水準2 l3 = pd.Series([9, 5]) #水準3 rp_data = pd.DataFrame({ 'Person':person, 'L1' : l1, 'L2' : l2, 'L3' : l3 }) rp_data

縦持ちに変換しておきます。
rp_data_melt = rp_data.melt(id_vars='Person', var_name='Level', value_name='Value') rp_data_melt

対応のある一元配置分散分析は、statsmodels.stats.anova.anovaRMクラスを用いて行うことが出来ます。
www.statsmodels.org
先程の縦持ち化した表、および必要な引数を与えてインスタンス化し、fit()メソッドを実行すればOKです。実際にやってみました。
import statsmodels.stats.anova as anova #水準(Level)はwithin引数に、リストとして与えることに注意. result = anova.AnovaRM(rp_data_melt, depvar='Value', subject='Person', within=['Level']).fit() #print(result) としても、結果をテキストとして表示できる. result.summary()
結果は以下の通りです。F値は31、p値は0.031と、教科書の例題通りの値が得られました。p値は5%(0.05)を下回っているので、カウンセリングの効果は有意に存在すると言えます。

繰り返しのある二元配置分散分析
使用するデータ
ここでは、ある化学反応について2通りの温度(50℃ or 100℃)、2通りの触媒(A or B)で実験を行い、生成物の量によってこれらの要因の影響を検証したいとします。各要因の組み合わせに対して、それぞれ4回の繰り返し実験を行ったところ、以下の表のような結果が得られたとします(数値は重量や濃度となどとします)。
それぞれの繰り返しにおける平均値は下表の通りです。これを見ると、温度や触媒の違いによって生成物の量には違いがありそうです。また温度の影響は触媒AとBで同様ではなさそうです。これらのことを分散分析で検定してみます。
statsmodelsを用いる方法
まずは先程の表をそのままデータフレーム化します。
import numpy as np import pandas as pd Temperature = np.array([50]*4 + [100]*4) #温度 CatalystA = np.array([2, 2, 0, 1, 8, 7, 6, 7]) #触媒A CatalystB = np.array([10, 8, 7, 9, 9, 11, 13, 10]) #触媒B data = pd.DataFrame({ 'Temperature' : Temperature, 'CatalystA' : CatalystA, 'CatalystB' : CatalystB }) data

続いて縦持ちに変換しておきます。
data_melt = data.melt(id_vars='Temperature', var_name='Catalyst', value_name=‘Amount') data_melt

ここで一度この表をプロットしてみます。statsmodelsにあるinteraction_plot関数を用いることで、交互作用図として簡単にプロットすることが出来ます(各要因(温度、触媒の種類)に対する生成物量の平均値をプロット)。
import seaborn as sns #必須ではない sns.set() from statsmodels.graphics.factorplots import interaction_plot fig = interaction_plot(data_melt['Temperature'], data_melt['Catalyst'], data_melt['Amount'], colors=['red','blue'])
結果として下図のように交互作用図が表示されます。これを見るとやはり、温度、触媒の種類はともに生成物量に対して主効果がありそうです。そして2本のグラフは平行となっていないことから、これら要因の間には交互作用が存在していそうです。

実際に二元配置分散分析をやってみます。手順としては(1)で記載した、statsmodelを用いた一元配置分散分析とほとんど同様です。
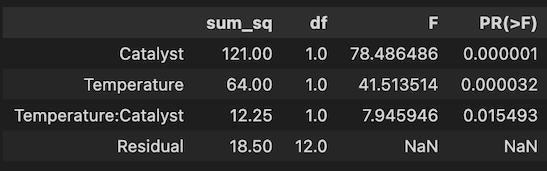
import statsmodels.api as sm from statsmodels.formula.api import ols #交互作用は「Temperature:Catalyst」のような書き方もOK formula = 'Amount ~ Temperature + Catalyst + Temperature*Catalyst' model = ols(formula, data_melt).fit() anova = sm.stats.anova_lm(model, typ=2) anova
ただし今回は二元配置ですので、モデルに用いる式は2つの要因を含める必要があります。縦持ち化した表(data_melt)の列名で指定すればOKです。更に今回は交互作用を考慮しますので、その場合は「Temperature*Catalyst」という具合に、要因同士を掛け合わせた記述の項も含めます。
結果は以下のようになります。温度(Temperature)および触媒の種類(Catalyst)はいずれもp値が5%(0.05)を下回っており、これらの要因は生成物量に対して、有意に主効果が存在すると言えます。またこれらの交互作用(Temperature:Catalyst)も同様に、p値が5%を下回っており、有意に存在すると言えます。