Pythonを用いた分散分析(ANOVA)あれこれ(2)
間が空いてしまいましたが(1)の続きとなります。こちらでは対応のある一元配置分散分析や、二元配置分散分析について纏めます。個人的な備忘録の色合いが強く、色々と端折っている部分があります。
※環境はJupyter Notebookの想定です。
※有意水準は全て5%(0.05)とします。
対応のある一元配置分散分析
使用するデータ
ここでは入門-統計学-第2版-という教科書171ページにある、対応のある一元配置分散分析の例題について、Pythonでトライしてみます。
こちらは2名の喫煙者Aさん、Bさんに対して、禁煙外来のカウンセリングが喫煙本数を変化させたかを検証する、という例題であり、以下の表がその結果となります。表内の数値は1日あたりの喫煙本数であり、水準1が相談前、水準2がカウンセリング1回目、水準3が2回目となります。
| 水準1 | 水準2 | 水準3 | 被験者平均 | |
|---|---|---|---|---|
| Aさん | 22 | 14 | 9 | 15 |
| Bさん | 14 | 8 | 5 | 9 |
| 群平均 | 18 | 11 | 7 | 12 |
statsmodelsを用いる方法
この例では同一の被験者に対する繰り返しの評価となるため対応関係が生じます。そのため被験者間変動(個人差による変動)を分離することが出来ます。実際にやってみるために、まずは表のデータフレームを作成します。
import numpy as np import pandas as pd from scipy import stats person = pd.Series(['A', 'B']) l1 = pd.Series([22, 14]) #水準1 l2 = pd.Series([14, 8]) #水準2 l3 = pd.Series([9, 5]) #水準3 rp_data = pd.DataFrame({ 'Person':person, 'L1' : l1, 'L2' : l2, 'L3' : l3 }) rp_data

縦持ちに変換しておきます。
rp_data_melt = rp_data.melt(id_vars='Person', var_name='Level', value_name='Value') rp_data_melt

対応のある一元配置分散分析は、statsmodels.stats.anova.anovaRMクラスを用いて行うことが出来ます。
www.statsmodels.org
先程の縦持ち化した表、および必要な引数を与えてインスタンス化し、fit()メソッドを実行すればOKです。実際にやってみました。
import statsmodels.stats.anova as anova #水準(Level)はwithin引数に、リストとして与えることに注意. result = anova.AnovaRM(rp_data_melt, depvar='Value', subject='Person', within=['Level']).fit() #print(result) としても、結果をテキストとして表示できる. result.summary()
結果は以下の通りです。F値は31、p値は0.031と、教科書の例題通りの値が得られました。p値は5%(0.05)を下回っているので、カウンセリングの効果は有意に存在すると言えます。

繰り返しのある二元配置分散分析
使用するデータ
ここでは、ある化学反応について2通りの温度(50℃ or 100℃)、2通りの触媒(A or B)で実験を行い、生成物の量によってこれらの要因の影響を検証したいとします。各要因の組み合わせに対して、それぞれ4回の繰り返し実験を行ったところ、以下の表のような結果が得られたとします(数値は重量や濃度となどとします)。
それぞれの繰り返しにおける平均値は下表の通りです。これを見ると、温度や触媒の違いによって生成物の量には違いがありそうです。また温度の影響は触媒AとBで同様ではなさそうです。これらのことを分散分析で検定してみます。
statsmodelsを用いる方法
まずは先程の表をそのままデータフレーム化します。
import numpy as np import pandas as pd Temperature = np.array([50]*4 + [100]*4) #温度 CatalystA = np.array([2, 2, 0, 1, 8, 7, 6, 7]) #触媒A CatalystB = np.array([10, 8, 7, 9, 9, 11, 13, 10]) #触媒B data = pd.DataFrame({ 'Temperature' : Temperature, 'CatalystA' : CatalystA, 'CatalystB' : CatalystB }) data

続いて縦持ちに変換しておきます。
data_melt = data.melt(id_vars='Temperature', var_name='Catalyst', value_name=‘Amount') data_melt

ここで一度この表をプロットしてみます。statsmodelsにあるinteraction_plot関数を用いることで、交互作用図として簡単にプロットすることが出来ます(各要因(温度、触媒の種類)に対する生成物量の平均値をプロット)。
import seaborn as sns #必須ではない sns.set() from statsmodels.graphics.factorplots import interaction_plot fig = interaction_plot(data_melt['Temperature'], data_melt['Catalyst'], data_melt['Amount'], colors=['red','blue'])
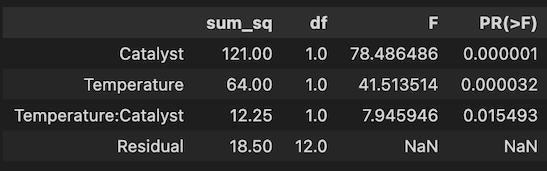
結果として下図のように交互作用図が表示されます。これを見るとやはり、温度、触媒の種類はともに生成物量に対して主効果がありそうです。そして2本のグラフは平行となっていないことから、これら要因の間には交互作用が存在していそうです。

実際に二元配置分散分析をやってみます。手順としては(1)で記載した、statsmodelを用いた一元配置分散分析とほとんど同様です。
import statsmodels.api as sm from statsmodels.formula.api import ols #交互作用は「Temperature:Catalyst」のような書き方もOK formula = 'Amount ~ Temperature + Catalyst + Temperature*Catalyst' model = ols(formula, data_melt).fit() anova = sm.stats.anova_lm(model, typ=2) anova
ただし今回は二元配置ですので、モデルに用いる式は2つの要因を含める必要があります。縦持ち化した表(data_melt)の列名で指定すればOKです。更に今回は交互作用を考慮しますので、その場合は「Temperature*Catalyst」という具合に、要因同士を掛け合わせた記述の項も含めます。
結果は以下のようになります。温度(Temperature)および触媒の種類(Catalyst)はいずれもp値が5%(0.05)を下回っており、これらの要因は生成物量に対して、有意に主効果が存在すると言えます。またこれらの交互作用(Temperature:Catalyst)も同様に、p値が5%を下回っており、有意に存在すると言えます。
Pythonを用いた分散分析(ANOVA)あれこれ(1)
Pythonを用いて分散分析(ANOVA)を行う方法について勉強する機会がありましたので、分かったことをあれこれ纏めました。(1)では対応のない一元配置分散分析+αについて纏めます。個人的な備忘録の色合いが強く、色々と端折っている部分があります。
※環境はJupyter Notebookの想定です。
※有意水準は全て5%(0.05)とします。
対応のない一元配置分散分析
使用するデータ
例えば100 gの樹脂サンプルを、3種の異なる溶媒A、B、Cにそれぞれ一定時間浸漬したときに、溶媒によって樹脂の溶け具合(浸漬後の重量)に差異が生じるか検証する実験を考えます。溶媒1種類につき5サンプルを評価し、浸漬後の重量を測定したところ、下表の結果が得られたとします。
| 溶媒A | 溶媒B | 溶媒C | |
|---|---|---|---|
| 1 | 76 | 79 | 81 |
| 2 | 81 | 71 | 87 |
| 3 | 83 | 80 | 82 |
| 4 | 76 | 77 | 87 |
| 5 | 82 | 71 | 88 |
| 平均 | 79.6 | 75.6 | 84.8 |
表を見ると差異が生じていそうですが、分散分析できちんと検定してみます。この場合…
- 帰無仮説:全ての溶媒間において、浸漬後重量の平均値に差異は存在しない
- 対立仮説:少なくとも一組の溶媒間において、浸漬後重量の平均値に差異が存在する
となります。
Scipyのstatsモジュールを用いる方法
おそらく一番手軽な方法です。scipy.stats.f_oneway()関数を使用します。
import numpy as np import pandas as pd from scipy import stats solventA = np.array([76, 81, 83, 76, 82]) solventB = np.array([79, 71, 80, 77, 71]) solventC = np.array([81, 87, 82, 86, 88]) #後々のために、一度データフレームにまとめておく data = pd.DataFrame({ 'A' : solventA, 'B' : solventB, 'C' : solventC }) fvalue, pvalue = stats.f_oneway(data['A'], data['B'], data['C']) # *以下のようにNumPy配列を直接与えることも可能 # fvalue, pvalue = stats.f_oneway(solventA, solventB, solventC) print(f"F-val:{fvalue:.4}, P-val:{pvalue:.4}")
結果は以下の通りとなります。f_oneway関数が返すのはF値とp値のみであり、分散分析表のような形で群間変動や誤差変動などを得ることは出来ないようです。
F-val:8.0201, P-val:0.006143
p値が5%(0.05)を下回ったので帰無仮説は棄却され、少なくとも一組の溶媒間において、浸漬後の重量の平均値には有意な差異が存在すると言えます。ただし具体的にどの溶媒間に差異が存在するのかは、分散分析では検定出来ません。
statsmodelsを用いる方法
統計解析用のライブラリであるstatsmodelsを用いて分散分析モデルを構築することが出来ます。まずはモデル化に向けて、先程のデータフレームを縦持ちに変換しておきます。
#先程のデータフレームをそのまま利用 data_melt = data.melt(var_name='Solvent', value_name='Weight') data_melt

そしてstatsmodelsで、最小二乗法(ols)を用いて分散分析モデルを構築します。
from statsmodels.formula.api import ols model = ols('Weight ~ Solvent', data=data_melt).fit() model.summary()
サマリーは以下のように表示されます。

後は構築したモデルを用いて、statsmodels.api.stats.anova_lm()により分散分析を実行出来ます。
import statsmodels.api as sm #引数typは、平方和のタイプ指定(いわゆるANOVA Type I, II, IIIなどと分類されるもの) #今回はtyp=2としたが、今回のように全ての溶媒に対して同数(5サンプル)のデータがある場合は #結果に差異は生じない anova = sm.stats.anova_lm(model, typ=2) anova
結果として、分散分析表がpandasデータフレームの形で得られます。F値、p値はScipyを用いたときと一致しました。また群間変動や誤差変動(sum_sq)、自由度(df)も出力されています。

補足:分散分析モデルの構築について
最初は、何故statsmodelsでは最小二乗法(ols)を用いたモデル化が必要になるのか?について理解が出来ていませんでしたが、色々と調べるうちに背景が分かってきました。数学的な正確性や厳密性には自信がありませんが、自分なりに理解出来たことをメモしてみます(以下の外部サイトが参考になりました)
一般化線形モデル(PDF資料)
正規方程式の導出と計算例 | 高校数学の美しい物語
pythonで統計学基礎:03 検定・分散分析 | 化学の新しいカタチ
今回の場合、分散分析モデルは以下のように定式化出来ます。溶媒Aにおける浸漬後の重量データを基準として、溶媒B、溶媒Cの場合はそれぞれ補正が加わるようなイメージです。
:浸漬後の重量
:溶媒Bの場合は1、そうでない場合は0となる変数
:溶媒Cの場合は1、そうでない場合は0となる変数
:誤差項
:パラメータ
ここで溶媒Xを用いたときのサンプルiについて、浸漬後の重量を、誤差項を
と表現すると、以下のように行列で表記が出来ます。
これをまとめて、以下のように表記することが出来ます。
これは一般線形モデルであり、誤差の二乗和が最小となる時のパラメータ(
)は、以下のように正規方程式を解くことで求めることが出来ます。
条件としてが正則である(逆行列を持つ)必要がありますが、今回のような定式化であれば満たすことが出来ます。実際にこの計算を自力でやってみました。
#先程の縦持ち化したデータフレームから、浸漬後の重量の値を取得 Y = data_melt['Weight'].to_numpy() X = np.array([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1]]).T #正規方程式を解く B = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y) print(B)
結果は以下の通りであり、となります。
[79.6 -4. 5.2]
これは先程、statsmodelsのolsが出力したサマリーにおける係数(coef)の値とピタリ一致します。つまり、olsを用いた分散分析モデル構築の中身は、このような演算ということになります。

は溶媒Aにおける浸漬後の重量の平均そのものであり、そこに
を加えた値は溶媒Bにおける平均(75.6)、
を加えた値は溶媒Cにおける平均(84.8)となります。
多重比較法(Tukey-Kramer法)
先述の通り分散分析では、具体的にどの溶媒間に差異が存在するのかは検定することが出来ません。そのような目的のためには多重比較法を用いる必要があります。
ただし「事前に分散分析を行い、その結果が有意であった場合に事後検定として多重比較法を行い、具体的にどの群間に有意差があるのかを検定する」という考え方は正しくないようです。
多重比較法には様々な種類があり、確かに分散分析を事前に行うことを前提とした手法(Scheffe法など)もありますが、一方で分散分析とは独立して群間の有意差の検定に適用可能な手法(Bonferroni法、Tukey-Kramer法など)もあります。もちろん後者においては、分散分析と結果が整合しない場合(分散分析では有意なのに、多重比較法では群間の有意差が出てこない、あるいはその逆)もあり得るようです。
分散分析と多重比較法の関係については、以下の外部サイトが参考になりました。
分散分析の下位に多重検定を置くな
検定の多重性 | ブログ | 統計WEB
統計検定を理解せずに使っている人のために III(PDF資料)
ここでは溶媒への樹脂浸漬データに対して、Tukey-Kramer法を用いた多重比較を行なってみます。
#先程の縦持ち化したデータフレームを使用 from statsmodels.stats.multicomp import pairwise_tukeyhsd pairwise_tukeyhsd(data_melt["Weight"], data_melt["Solvent"]).summary()
サマリーは以下のように表示されます。溶媒B、C間では、p値(p-adj)が5%(0.05)を下回っており、浸漬後重量の平均値に有意差ありとなります(その場合「reject」がTrueとなります)。

今回の結果は分散分析とも整合しておりますが、先述の通りTukey-Kramer法は分散分析とは独立した手法であり、必ず整合するとは限らないことには注意が必要です。
統計学の備忘録的な学習メモ(2)
統計学の備忘録的な学習メモ(1)に引き続き、Python(Scipyなど)を用いた統計学の勉強に関するメモです。(2)では主に様々な分布および検定についてまとめています。
個人的な備忘録の意味合いが強く、他記事と書き方が異なっており、説明なども少なめです。今後は予告なく内容を追加・修正するかもしれません。
※環境はJupyter Notebookの想定です。
- インポートするライブラリ
- 二項分布のプロット
- 二項分布を用いた検定
- t分布のプロット
- t分布を用いた母平均の区間推定
- 1群のt検定
- 対応のある2群のt検定
- 対応のない2群のt検定(Welchのt検定)
- 母比率の区間推定
- 母比率の区間推定に向けたサンプルサイズの決定
- カイ二乗分布のプロット
- カイ二乗分布のシミュレーション
- ピアソンのカイ二乗検定
- カイ二乗分布を用いた母分散の区間推定
- 等分散性の検定
インポートするライブラリ
import numpy as np import pandas as pd import scipy as sp from scipy import stats from scipy.special import gamma from matplotlib import pyplot as plt import seaborn as sns sns.set()
二項分布のプロット
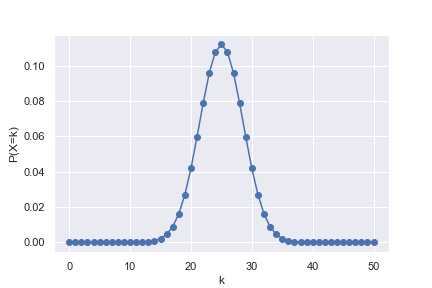
公正なコイン(きちんと表、裏がそれぞれ1/2の確率で出る)を50回投げて、そのうち表がk回出る確率をプロット。
n = 50 #試行回数 p = 1/2 #確率 k = np.arange(0, n + 1, 1) #試行回数n回のうち、確率pの事象がk回起こる確率 #離散的なデータなので、pdfではなくpmf関数となる pk = stats.binom.pmf(k, n, p) #二項分布を折れ線としてプロット plt.plot(k, pk, marker='o') plt.xlabel("k") plt.ylabel("P(X=k)") plt.show()
二項分布を用いた検定
コインを20回投げたら表が15回出たとき、コインが公正と言えるかを検定する。
print(stats.binom_test(15, 20, 1/2)})
結果はおよそ0.0414となり、5%有意水準(0.05)では「コインが公正である」という帰無仮説は棄却される。
別の方法で確認する。表が5回以下となる確率、15 回以上となる確率をそれぞれ求める。当然ながら両者は一致し、またこれらの和が先程の0.0414と一致することが確認出来た。
lower = stats.binom.cdf(5, 20, 1/2) #公正なコインの表が、20回中0〜5回出る確率 upper = 1 - stats.binom.cdf(14, 20, 1/2) #公正なコインの表が、20回中15〜20回出る確率 print(f'lower = {lower:.4}') print(f'upper = {upper:.4}') print(f'upper + upper = {lower + upper:.4}')
lower = 0.02069
upper = 0.02069
upper + upper = 0.04139
t分布のプロット
さまざまな自由度(df)におけるt分布の形をプロットしてみる。標準正規分布も併せてプロットする。
df_array = np.arange(1, 10, 1) fig = plt.figure(figsize=(10, 5)) ax = fig.add_subplot(111) x = np.linspace(-4, 4, 100) for i in range(0, len(df_array)): y = stats.t.pdf(x, df=df_array[i]) ax.plot(x, y, label=f'df = {df_array[i]}', alpha=0.6) ax.plot(x, stats.norm.pdf(x), label='norm', alpha=0.6) ax.set_xlabel('t or z') ax.set_ylabel('probability density') plt.legend()
自由度の値が大きくなるほど、標準正規分布(norm表記)に近づくことが確認出来た。

t分布を用いた母平均の区間推定
あるサンプルについて、母集団の平均の95%信頼区間を推定する。
sample = np.array([10.1, 9.8, 11.1, 10.5, 9.6, 10.8]) mu = sp.mean(sample) print(f'標本平均 = {mu:.4}') sigma = sp.std(sample, ddof=1) #不偏分散の平方根 df = len(sample) - 1 print(f'自由度 = {df}') se = sigma/sp.sqrt(len(sample)) #標本標準誤差 interval = stats.t.interval(alpha = 0.95, df = df, loc = mu, scale = se) print(f'下側信頼限界 = {interval[0]:.4}') print(f'上側信頼限界 = {interval[1]:.4}')
標本平均 = 10.32
自由度 = 5
下側信頼限界 = 9.703
上側信頼限界 = 10.93
別の方法でも確認する。t.ppf()関数を用いて2.5%点、97.5%点を自分で計算し、信頼限界を求めてみる。
#mu、se、dfは先程の例と同じであるとする #※t分布は対称形なので、t_975 = -t_025と求めることも出来る t_025 = stats.t.ppf(q = 0.025, df = df) print(f’2.5%点 = {t_025:.4}') t_975 = stats.t.ppf(q = 0.975, df = df) print(f'97.5%点 = {t_975:.4}') print(f'下側信頼限界 = {mu + t_025 * se:.4}') print(f'上側信頼限界 = {mu + t_975 * se:.4}')
信頼区間は先程と確かに一致することが確認出来た。
2.5%点 = -2.571
97.5%点 = 2.571
下側信頼限界 = 9.703
上側信頼限界 = 10.93
※なお信頼区間の正しい解釈は中々難しい。今回の結果を「母平均の値は95%の確率で、9.703〜10.93の間に存在する」と考えるのは正しくない模様(母平均の真の値は知るのが困難だけで、あらかじめ確定した定数であり、信頼区間の間に存在する/しないは本来はっきり定まっているため、95%の確率で存在する…という考え方は出来ない)
正しい解釈は、また別のサンプルを母集団から同様の手順で抽出して、信頼区間の推定を行う…という手順を100回繰り返した場合、そのうち95回は信頼区間の間に母平均の値が存在する、という具合のようです。以下のサイトが参考となりました。
19-3. 95%信頼区間のもつ意味 | 統計学の時間 | 統計WEB
1群のt検定
例えば、平均厚み50 mm狙いで量産されている製品について、サンプルを10個抽出して厚みを実測したところ、以下の表のようになった(標本平均 50.67)。
| 50.2 | 51.4 | 49.7 | 51.1 | 49.4 | 50.9 | 52.1 | 51.4 | 50.9 | 49.6 |
この製品の平均厚みは本当に50 mmであると言えるか?。1群のt検定ではこうした問題に対する判断を行うことが出来る。有意水準は5%とする。
sample = np.array([50.2, 51.4, 49.7, 51.1, 49.4, 50.9, 52.1, 51.4, 50.9, 49.6]) mu = sp.mean(sample) print(f'標本平均 = {mu:.4}') df = len(sample) - 1 print(f'自由度 = {df}') sigma = sp.std(sample, ddof=1) #不偏分散の平方根 se = sigma / sp.sqrt(len(sample)) #標本標準誤差 t_value = (mu - 50)/se #母平均は50という仮定に基づく print(f't値 = {t_value:.4}') alpha = stats.t.cdf(t_value, df = df) #標本のt値を、t分布がを下回る確率 print(f'α = {alpha:.4}') print(f'p値 = {(1 - alpha) * 2:.4}') #両側検定なので *2 となる #stats.t.sf(t_value, df = df) #t.sf関数(生存関数)を用いれば、(1-alpha)の値が直接求まる。
p値が約0.043となり、有意水準5%(0.05)を下回った。サンプルの平均厚みは50 mmとは有意に異なると言える。
標本平均 = 50.67
自由度 = 9
t値 = 2.349
α = 0.9783
p値 = 0.04337
1群のt検定は、専用の関数を用いてもっと簡単に行うことも可能である。
#sampleは先程の例と同じであるとする t_value, p_value = stats.ttest_1samp(sample, 50) print(f't値 = {t_value:.4}') print(f'p値 = {p_value:.4}')
t値、p値は確かに先程の例と一致している。
t値 = 2.349
p値 = 0.04337
母集団(すなわち製品全体)の平均厚みについて、信頼区間の推定も行ってみる。
#mu、se、dfは先程の例と同じであるとする interval = stats.t.interval(alpha = 0.95, df = df, loc = mu, scale = se) print(f'下側信頼限界 = {interval[0]:.4}') print(f'上側信頼限界 = {interval[1]:.4}')
信頼区間は50.02〜51.32となり、50を含まないことが確認出来た。
下側信頼限界 = 50.02
上側信頼限界 = 51.32
対応のある2群のt検定
例えば、5人の被験者(A〜E)について、異なる状態1、2における心拍数を測定した結果を測定した結果、以下の表のようになった。
| A | B | C | D | E | |
| 状態1 | 105 | 99 | 94 | 88 | 110 |
| 状態2 | 96 | 93 | 87 | 90 | 102 |
状態1と2の違いが、心拍数に影響を及ぼしているだろうか?2群のt検定ではこうした問題に対する判断を行うことが出来る。有意水準は5%とする。
今回は同じ被験者に対するデータなので、状態1、2のデータはペアとして考えることが出来る。この場合は対応のある2群のt検定を行う。まず状態1、2の差分を取って、差分に対して平均が0となるかどうか、1群のt検定を行えば良い。
data = pd.DataFrame({
'person' : ['A','B','C','D','E','A','B','C','D','E'],
'state' : ['S1','S1','S1','S1','S1','S2','S2','S2','S2','S2'],
'heart_rate' : [105, 99, 94, 88, 110, 96, 93, 87, 90, 102],
})
#状態(state)別の、心拍数の数値データを抜き出す
state1 = np.array(data.query('state == "S1"')['heart_rate'])
state2 = np.array(data.query('state == "S2"')['heart_rate'])
#状態1、2の差分を計算する
diff = state1 - state2
#差分に対して、母平均が0と異なるか否か、1群のt検定を行う
#0と異なると言える場合は、状態1、2における心拍数は有意に異なると言える
t_value, p_value = stats.ttest_1samp(diff, 0)
print(f't値 = {t_value:.4}')
print(f'p値 = {p_value:.4}')
p値は約0.046となり、有意水準5%(0.05)を下回った。状態1と2の違いは、有意に心拍数に影響を及ぼしていると言える。
t値 = 2.85
p値 = 0.04638
対応のある2群のt検定も、専用の関数で簡単に行うことが可能である。結果は先程と全く同じとなる。
t_value, p_value = stats.ttest_rel(state1, state2) print(f't値 = {t_value:.4}') print(f'p値 = {p_value:.4}')
対応のない2群のt検定(Welchのt検定)
例えば、異なるクラスにおけるテストの平均点の比較、異なる工場で作られた同種製品の平均サイズの比較など、それぞれ独立したデータ同士には対応のない2群のt検定を適用する。
この場合、「かつては」2群の分散が等しいか異なるかをまず判定し(F検定で行う)、それによって2通りの方法を使い分ける必要がある、という考えが主流であったとのこと。しかし最近では…
- 分散が異なる場合用とされていた方法(Welchのt検定)は、分散が等しい場合に適用しても支障がないこと
- F検定 → t検定 の2段階を経ると、多重性の問題が生じること
といった理由によって、最初からWelchのt検定を行う考えが主流になっているとのことである。
【参考となった外部サイト】
等分散検定から t検定,ウェルチ検定,U検定への問題点
検定の多重性を分かりやすく解説します【F検定⇒t検定はダメ?】
24-4. 対応のない2標本t検定 | 統計学の時間 | 統計WEB
先程の心拍数のデータを、対応のないデータと仮定して、Welchのt検定を試してみる。
#equal_var = Falseとすると、分散が異なる2群向けのWelchのt検定が適用される #本文で記載した通り、常にWelchのt検定でも支障がないとのこと t_value, p_value = stats.ttest_ind(state1, state2, equal_var = False) print(f't値 = {t_value:.4}') print(f'p値 = {p_value:.4}')
使用データ自体は先程と同じだが、結果はもちろん異なっている。p値が約0.270となり有意水準5%(0.05)を上回っているので、有意差が得られないという結論となる。
t値 = 1.199
p値 = 0.2697
確認のために、Welchのt検定の式に従って自力でも計算してみる。state1、2の標本サイズを、標本平均を
、不偏分散を
とすると、t値は以下の式で計算出来る。
自由度は以下の式で近似的に求めることが出来る。
mean1 = state1.mean() mean2 = state2.mean() var1 = state1.var(ddof=1) var2 = state2.var(ddof=1) n1 = state1.size n2 = state2.size t_value = (mean1 - mean2) / np.sqrt((var1/n1 + var2/n2)) print(f't値= {t_value:.4}') df = (var1/n1 + var2/n2)**2 / (var1**2/(n1**2*(n1 - 1)) + var2**2/(n2**2*(n2 - 1))) alpha = stats.t.cdf(t_value, df = df) print(f'p値 = {(1-alpha)*2:.4}')
結果は先程ときちんと一致することが確認出来た。
t値 = 1.199
p値 = 0.2697
母比率の区間推定
例えば、無作為に選んだ100人に好きなプログラミング言語のアンケートを実施したところ、15人がPythonと答えたとする(比率:15/100 = 0.15、15%)。ここから、世の中におけるPython好きな人の比率について、95%信頼区間を推定してみる。これは母比率の区間推定であり、binom.interval関数を用いれば簡単に行うことが出来る。
sample_size=100 #サンプルサイズ prop = 0.15 #比率(標本比率) interval = stats.binom.interval(alpha = 0.95, n = sample_size, p = prop) #intervalには比率ではなく数(この場合はPython好きな人数の下限値、上限値)が返されることに注意. #比率に直すには、サンプルサイズで割る必要がある. print(f'下側信頼限界 = {interval[0]/sample_size:.4}') print(f'上側信頼限界 = {interval[1]/sample_size:.4}')
結果は以下の通りであり、Python好きな人の比率の95%信頼区間は、0.08〜0.22(8%〜22%)となる。標本平均15%に対して±7%の幅を持つことになる。
下側信頼限界 = 0.08
上側信頼限界 = 0.22
別の方法でも確認する。binom.ppf()関数を用いて2.5%点、97.5%点を自分で計算し、信頼限界を求めてみる。結果は先程の例と全く同じであり、2.5%点、97.5%点はそのまま、Python好きな人数の下限値、上限値である。
#sample_size, propは先程の例と同じとする p_025 = stats.binom.ppf(q=0.025, n=sample_size, p=prop) p_975 = stats.binom.ppf(q=0.975, n=sample_size, p=prop) print(f'下側信頼限界 = {p_025/sample_size:.4}') print(f'上側信頼限界 = {p_975/sample_size:.4}')
母比率の区間推定に向けたサンプルサイズの決定
先程の例では標本比率15%に対して、95%信頼区間は±7%の幅を持つという結果となった。
ここで逆に、95%信頼区間の幅を確実に±2%以内に収められるよう、サンプルサイズ(アンケート対象とする人数)を決定したいとする。母比率を、標本比率を
、サンプルサイズを
、信頼係数を
とすると、信頼区間は以下の式で求められる。
ただしは
に対応する標準正規分布の値である。
が95%の場合、
は標準正規分布の2.5%点(または97.5%点)である1.96となる。
式より、の部分の値が、まさに±何%となるかの幅そのものとなる。95%信頼区間の幅を±2%(0.02)以内に収めるために必要なサンプルサイズは、以下の式を
について解けば求められる。
実際に解くと以下の通りとなる。
ただし先程の例では15%(0.05)であったが、これは実際に100人にアンケートをした結果の値である。しかしここでは、アンケートを行う前に対象人数を決定したい状況を想定しているため、
はまだ未知の値である。
そこで1つの方法としてと仮定する。これは
の部分が最大となり、必要なサンプルサイズが最多となるワーストケースとなってしまうが、その場合でも±2%に収まれば確実に目的を達成できる。実際に計算を試してみた。
alpha = 0.95 #信頼係数. prop = 0.5 #標本比率だが, 今回は未知であるので, ワーストケースの0.5と仮定 scope = 0.02 #信頼区間の幅を, ±何%以内に収めたいかの値 #norm.ppf関数が負の値を返す場合でも、二乗しているので、問題なく計算できる sample_size = (stats.norm.ppf((1 - alpha)/2) / scope)**2 * prop * (1 - prop) #サンプルサイズは整数なので、丸めて表示する print(f'必要なサンプルサイズ:{round(sample_size)}')
結果は以下の通りであり、最低でも2401人にアンケートを取れば良いことが分かる。
必要なサンプルサイズ:2401
また別の方法として、の値を仮定してしまうことも考えられる。例えば過去の知見から、比率が20%を超えることはまず無い、などと見積もれる場合は、ワーストケースとして
を仮定すれば良い(上記のコードで、prop = 0.2とする)。この場合の必要人数は1537人と、より少なくなる。
カイ二乗分布のプロット
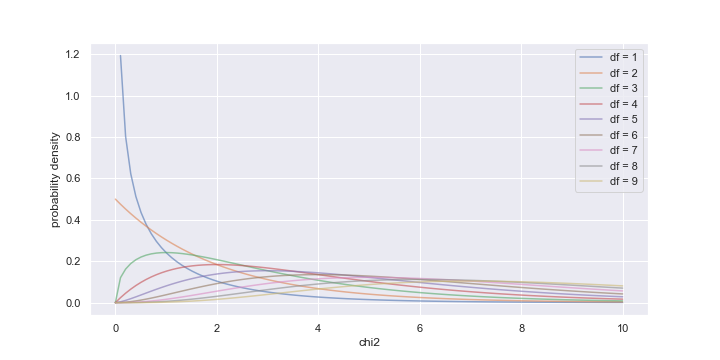
さまざまな自由度(df)におけるカイ二乗分布の形をプロットしてみる。
df_array = np.arange(1, 10, 1) fig = plt.figure(figsize=(10, 5)) ax = fig.add_subplot(111) x = np.linspace(0, 10, 100) for i in range(0, len(df_array)): y = stats.chi2.pdf(x, df=df_array[i]) ax.plot(x, y, label=f'df = {df_array[i]}', alpha=0.6) ax.set_xlabel('chi2') ax.set_ylabel('probability density') plt.legend()
カイ二乗分布のシミュレーション
正規分布に従う母集団から、サイズ10の標本を抽出して、定義通りにカイ二乗値を計算することを10,000回繰り返すシミュレーションを行い、そこからカイ二乗分布をプロットしてみる。まずは母平均が既知であるという前提で計算を行なう。
#平均50, 標準偏差10(分散100)の正規分布を利用 p_mean = 50 p_std = 10 population = stats.norm(loc=p_mean, scale=p_std) sample_size = 10 #標本サイズ n_trial = 10000 chi2_array = np.zeros(n_trial) for i in range(0, n_trial): sample = population.rvs(sample_size) #定義通りにカイ二乗値を計算する。 #母平均p_meanは既知という前提で計算に使用 chi2 = np.sum([((x - p_mean)/p_std)**2 for x in sample]) chi2_array[i] = chi2 sns.distplot(chi2_array, kde=False, norm_hist = True) x = np.arange(start = 0, stop = 30, step = 0.1) plt.plot(x, stats.chi2.pdf(x=x, df=sample_size), label=f'df = {sample_size}') plt.plot(x, stats.chi2.pdf(x=x, df=sample_size-1), label=f'df = {sample_size-1}') plt.xlabel("chi2") plt.ylabel("Frequency") plt.legend() plt.show()
母平均を既知として計算に使用しているので、自由度(df)は標本サイズ(今回は10)と等しくなる。実際にシミュレーションで得られたヒストグラムを、自由度10および9の理論的なカイ二乗分布のカーブと重ねてみると、自由度10の方に合致する。

今度は母平均は未知として、標本平均を用いて計算を行う。この場合は自由度が1つ減少する。
#カイ二乗値の計算を行う部分のみ抜粋 for i in range(0, n_trial): sample = population.rvs(sample_size) s_mean = sample.mean() #標本平均 #定義通りにカイ二乗値を計算する。 #今度は母平均は未知という前提で、標本平均s_meanを計算に使用 chi2 = np.sum([((x - s_mean)/p_std)**2 for x in sample]) chi2_array[i] = chi2
先程同様に得られたヒストグラムを、自由度10および9の理論的なカイ二乗分布のカーブと重ねてみると、今度は自由度9の方に合致した。

ピアソンのカイ二乗検定
例えば、ある製品を生産する工場AとBがあり、不良品の発生個数について以下のようなデータが得られたとする。
| 不良品 | 良品 | |
| A | 780 | 37220 |
| B | 20 | 1980 |
工場Aの不良率は約2%、工場Bは約1%だが、これらは有意な差と言えるか?(適当なデータなので、どちらも不良品出し過ぎ!というツッコミは無しでw)
ピアソンのカイ二乗検定で検討する(有意水準は5%とする)。最初にデータのクロス集計表を作る。
data = pd.DataFrame({
'factory':['A', 'A', 'B', 'B'],
'quality':['good', 'defective', 'good', 'defective'],
'quantity':[37220, 780, 1980, 20]
})
cross = pd.pivot_table(
data=data,
values='quantity',
aggfunc=sum,
index='factory',
columns='quality'
)
cross
quality defective good
factory
A 780 37220
B 20 1980
集計表が出来れば、専用の関数で簡単に検定を行うことが可能である。
#correction=Trueにすると、イェーツの補正という処理が行われる #度数の極端に小さい項目が、集計表に含まれる場合に適用するようだが、その妥当性については諸説ある模様 #元々の原理通りに検定を行うのであれば、Falseにしておく chi2, p_value, df, exp_freq_array = stats.chi2_contingency(cross, correction=False) print(f'カイ二乗値 = {chi2}') print(f'p値 = {p_value}') print(f'自由度 = {df}') print(f'期待度数表\n{exp_freq_array}')
p値は約0.001となり、5%(0.05)を下回るので、工場AとBの不良率には有意な差があると言える。
カイ二乗値 = 10.74
p値 = 0.001048
自由度 = 1
期待度数表
[[ 760. 37240.]
[ 40. 1960.]]
期待度数表について、手計算と比較して確認する。それぞれの合計値を記載した集計表を示す。
| 不良品 | 良品 | 合計 | |
| A | 780 | 37220 | 38000 |
| B | 20 | 1980 | 2000 |
| 合計 | 800 | 39200 | 40000 |
もし工場A、Bの違いを無視してトータルで見た場合、不良率は800/40000 = 2%である。
このトータルの不良率通りになる場合、それぞれの工場における不良品個数は以下の通りになるはずである。これが期待度数となる。
- A工場:38000 * 2% = 760個
- B工場:2000 * 2% = 40個
良品も併せた期待度数表を以下に示す。確かに先程の出力と一致した。
| 不良品 | 良品 | |
| A | 760 | 37240 |
| B | 40 | 1960 |
定義通りにピアソンのカイ二乗値も計算してみる。結果は10.74となり確かに先程の出力と一致した。
cross_array = np.array([[780, 37220],[20, 1980]]) exp_freq_array = np.array([[760, 37240],[40, 1960]]) chi2 = 0 for i in range(0, 2): for j in range(0, 2): chi2 += (cross_array[i][j] - exp_freq_array[i][j]) ** 2 / exp_freq_array[i][j] print(f'カイ二乗値 = {chi2:.4}')
カイ二乗分布を用いた母分散の区間推定
カイ二乗分布を用いて、母分散の区間推定を行ってみる。題材として東京大学教養学部統計学教室 編『基礎統計学I 統計学入門』東京大学出版会の練習問題11.6 ii)を解いてみる。東京における10日間の温度データから、その母分散の信頼区間を信頼係数95%で求める。
#東京大学出版会 統計学入門 問題11.6 ii)より data = np.array([21.8, 22.4, 22.7, 24.5, 25.9, 24.9, 24.8, 25.3, 25.2, 24.6]) df = data.size - 1 var = data.var(ddof=1) chi2 = stats.chi2(df = df) #t分布のときと異なり、カイ二乗値は分母に来るため、その値が大きいほうが下限側になることに注意 lower = df * var / chi2.ppf(1.0 - 0.05/2) upper = df * var / chi2.ppf(0.05/2) print(f'信頼区間 [{lower:.4}, {upper:.4}]')
得られた信頼区間は、書籍記載の練習問題の解答ときちんと一致した。
信頼区間 [0.9173, 6.462]
interval関数を用いた方法も試してみる。もちろん結果は先程と一致する。
data = np.array([21.8, 22.4, 22.7, 24.5, 25.9, 24.9, 24.8, 25.3, 25.2, 24.6]) df = data.size - 1 var = data.var(ddof=1) interval = stats.chi2.interval(alpha = 0.95, df = df) #先程と同様、どちらが上限/下限となるかに注意 lower = df * var / interval[1] upper = df * var / interval[0] print(f'信頼区間 [{lower:.4}, {upper:.4}]')
等分散性の検定
正規分布に従う2つの群について、母集団の分散が等しいか否かを検証する場合はF検定を行う。ただしScipyのstatsモジュールには、F検定を簡単に直接行える関数は用意されていない模様なので、教科書などを参考に自前で実装してみる。
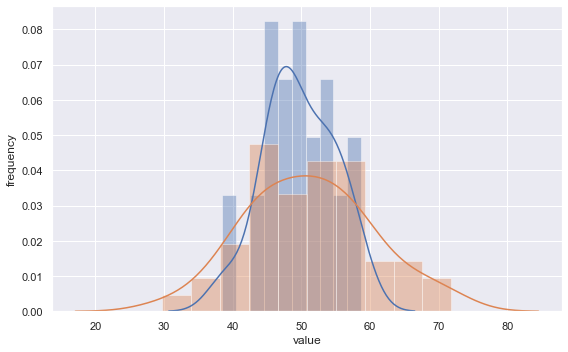
#F検定を行う関数. 2群のデータをそれぞれ引数で与える. def ftest(d1, d2): var1 = d1.var(ddof=1) var2 = d2.var(ddof=1) df1 = d1.size - 1 df2 = d2.size - 1 #F統計量の計算.常に値が1より大きくなるようにする. f_value = var1/var2 if var1 > var2 else var2/var1 p1 = stats.f.cdf(f_value, df1, df2) p2 = stats.f.sf(f_value, df1, df2) p_value = min(p1, p2) * 2 return f_value, p_value #分散が異なる正規分布から、サイズの異なる2群をランダムに生成して与えてみる. #なお平均(50)の違いは、当然ながら結果には影響しない. np.random.seed(1) data1 = stats.norm.rvs(loc = 50, scale = 5, size = 30) data2 = stats.norm.rvs(loc = 50, scale = 10, size = 50) f_value, p_value = ftest(data1, data2) print(f" F-value = {f_value:.4}, P-value = {p_value:.4}")
結果は以下の通りであり、p値が有意水準5%(0.05)を下回ったので、実際に2群の分散が有意に異なることを検証できた。
参考までに、今回の2群をヒストグラムで描いて見ると下図のようになる。
なおstatsモジュールには、実はF検定とは別の、等分散性の検定を行う関数が用意されている(Bartlett検定、Levene検定)。これらは共に、本来は3群以上に対して適用する手法とのことであるが、2群でも適用可能であり、statsモジュールにおいてはF検定ではなくこれらを用いる想定である模様。
これらの原理や使い分けについてはあまり理解出来ていないが(F検定と同様、正規分布に従う2群であればBartlett検定を、そうでない場合はLevene検定を適用する?)、試しに先程F検定を行った2群に対して使用してみる。
#data1, data2は先程F検定を行ったものと同じ data1 = stats.norm.rvs(loc = 50, scale = 5, size = 30) data2 = stats.norm.rvs(loc = 50, scale = 10, size = 50) #先程同様の、自作関数によるF検定 f_value, p_value = ftest(data1, data2) print(f"Ftest : F-value = {f_value:.4}, P-value = {p_value:.4}") #Bartlett検定 stat, p_value = stats.bartlett(data1, data2) print(f"Bartlett : statistics = {stat:.4}, P-value = {p_value:.4}") #Levene検定 stat, p_value = stats.levene(data1, data2) print(f"Levene : statistics = {stat:.4}, P-value = {p_value:.4}")
結果は以下の通り。いずれの手法でもp値は有意水準5%(0.05)を下回っている。
Ftest : F-value = 3.252, P-value = 0.0002677
Bartlett : statistics = 10.83, P-value = 0.0009991
Levene : statistics = 8.886, P-value = 0.003831
統計学の備忘録的な学習メモ(1)
現在、故あってPython(Scipyなど)を使って統計学を基礎から勉強しております。その中で特に備忘録として残しておきたいことをメモして行こうと思います。個人的な備忘録の意味合いが強く、他記事と書き方が異なっており、説明なども少なめです。今後は予告なく内容を追加・修正するかもしれません。
※環境はJupyter Notebookの想定です。
インポートするライブラリ
import numpy as np import pandas as pd import scipy as sp from scipy import stats from scipy.special import gamma from matplotlib import pyplot as plt import seaborn as sns sns.set()
さまざまな統計量の表示
Scipyの関数を用いて、(1, 2, 3, 4, 5)という単純なサンプルの様々な統計量を表示する。
sample = np.array([1, 2, 3, 4, 5]) print(f'サンプルサイズ(N) = {len(sample)}') print(f"合計 = {sp.sum(sample)}") print(f"平均 = {sp.mean(sample)}") print(f"最大値 = {sp.amax(sample)}") print(f"最小値 = {sp.amin(sample)}") print(f"中央値 = {sp.median(sample)}") print(f"第1四分位数 = {stats.scoreatpercentile(sample, 25)}") print(f"第3四分位数 = {stats.scoreatpercentile(sample, 75)}") print(f"標本分散(分母が N) = {sp.var(sample, ddof=0)}") print(f"不偏分散(分母が N-1) = {sp.var(sample, ddof=1)}") print(f"標本標準偏差 = {sp.std(sample, ddof=0):.4f}") print(f"不偏分散の平方根 = {sp.std(sample, ddof=1):.4f}")
サンプルサイズ(N) = 5
合計 = 15
平均 = 3.0
最大値 = 5
最小値 = 1
中央値 = 3.0
第1四分位数 = 2.0
第3四分位数 = 4.0
標本分散(分母が N) = 2.0
不偏分散(分母が N-1) = 2.5
標本標準偏差 = 1.4142
不偏分散の平方根 = 1.5811
分散の関数を自前で実装して、比較してみる
#自前の標本分散関数 def my_varp(x): mu = sp.mean(x) v = sp.sum((x - mu) ** 2) / len(x) return v #自前の不偏分散関数 def my_var(x): mu = sp.mean(x) v = sp.sum((x - mu) ** 2) / (len(x) - 1) return v print(f"標本分散(自前) = {my_varp(sample)}") print(f"不偏分散(自前) = {my_var(sample)}") print(f"標本標準偏差(自前)= {np.sqrt(my_varp(sample)):.4f}") print(f"不偏分散の平方根(自前)= {np.sqrt(my_var(sample)):.4f}")
自前の関数による計算結果は、確かにScipyと一致している。
標本分散(自前) = 2.0
不偏分散(自前) = 2.5
標本標準偏差(自前)= 1.4142
不偏分散の平方根(自前)= 1.5811
Pandasでも基礎的な統計量の表示は出来る。describe関数を用いると要約統計量を表示してくれる(表示される標準偏差(std)は、実際は不偏分散の平方根である模様)
sr = pd.Series([1, 2, 3, 4, 5]) print(f"合計(pd版) = {sr.sum()}") print(f"平均(pd版)= {sr.mean()}") print(f"標本分散(pd版) = {sr.var(ddof=0)}") print(f"不偏分散(pd版) = {sr.var(ddof=1)}") print(f"標本標準偏差(pd版) = {sr.std(ddof=1):.4}") print(f"標準偏差平方根(pd版) = {sr.std(ddof=1):.4}") print("-----") sr.describe()
合計(pd版) = 15
平均(pd版)= 3.0
標本分散(pd版) = 2.0
不偏分散(pd版) = 2.5
標本標準偏差(pd版) = 1.4142
不偏分散の平方根(pd版) = 1.5811
-----
count 5.000000
mean 3.000000
std 1.581139
min 1.000000
25% 2.000000
50% 3.000000
75% 4.000000
max 5.000000
dtype: float64
不偏分散の平方根に関する混乱
母集団から抽出した、サンプルサイズの標本
がある場合
- 標本に対する統計量
| 標本平均 | |
| 標本分散 | |
| 標本標準偏差 |
- 母集団の母数を標本から推定する統計量
| 平均 | ※標本平均がそのまま、母平均の不偏推定量となる |
| 不偏分散 | |
| 不偏分散の平方根 |
この中でも不偏分散の平方根については、最初に手にした統計学の教科書では「不偏標準偏差」と呼ばれていました。しかし別の教科書では、これは母標準偏差に対する不偏推定量ではないので、不偏標準偏差という言い方はしないと書かれており、非常に混乱しました。
ネットでも色々調べたところ、この辺りの統計量の呼び方や、どんな記号を割り当てるかは非常に混乱しているようです。自分でもシミュレーション(後で掲載)をやってみて、これが母標準偏差に対する不偏推定量ではないことが腑に落ちましたので、不偏分散の平方根とそのまま呼ぼうと思います。非常に参考となった外部サイトをいくつか示します。
不偏標準偏差とは?:統計検定を理解せずに使っている人のために
不偏分散とは?n-1で割る理由を簡単にわかりやすくエクセルの関数を解説!|いちばんやさしい、医療統計
不偏分散の平方根は標準偏差の不偏推定量か | ブログ | 統計WEB
サンプルサイズと各統計量のシミュレーション
サンプルサイズを増やして行ったときに、各統計量がどのように変化するかをシミュレーションする
#必要なライブラリはインポート済みとする #乱数のシードを固定 np.random.seed(1) #平均50, 標準偏差10、分散100の正規分布を利用 loc = 50 scale = 10 population = stats.norm(loc = loc, scale = scale) #シミュレーション対象とするサンプルサイズ sample_size = np.array([10, 100, 1000, 10000]) sample_mean_array = np.zeros(len(sample_size)) #平均を格納 sample_varp_array = np.zeros(len(sample_mean_array)) #標本分散を格納 sample_var_array = np.zeros(len(sample_mean_array)) #不偏分散を格納 sample_stdp_array = np.zeros(len(sample_mean_array)) #標本標準偏差を格納 sample_std_array = np.zeros(len(sample_mean_array)) #不偏分散の平方根を格納 #試行回数は1回として、各サンプルサイズにおける統計量をシミュレートする for i in range(0, len(sample_size)): sample = population.rvs(size = sample_size[i]) sample_mean_array[i] = sp.mean(sample) sample_varp_array[i] = sp.var(sample, ddof=0) sample_var_array[i] = sp.var(sample, ddof=1) sample_stdp_array[i] = sp.std(sample, ddof=0) sample_std_array[i] = sp.std(sample, ddof=1) #各サンプルサイズにおける統計量を表示 for i in range(0, len(sample_size)): print(f'サンプルサイズ {sample_size[i]}') print(f'・母平均 = {loc}') print(f'・母分散 = {scale ** 2}') print(f'・母標準偏差 = {scale}') print(f'・母標準誤差 = {scale/sp.sqrt(sample_size[i]):.5}') print(' ------') print(f'・標本平均 = {sample_mean_array[i]:.5}') print(f'・標本分散 = {sample_varp_array[i]:.5}') print(f'・標本標準偏差 = {sample_stdp_array[i]:.5}') print(f'・標本標準誤差 = {sp.sqrt(sample_varp_array[i]/sample_size[i]):.5}') print(' ------') print(f'・不偏分散 = {sample_var_array[i]:.5}') print(f'・不偏分散の平方根 = {sample_std_array[i]:.5}') print(f'・不偏標準誤差(不偏分散の平方根/√N) = {sample_std_array[i]/sp.sqrt(sample_size[i]):.5}') print('\n')
試行1回のためか、サンプルサイズ100でも不偏推定量と母数のズレが大きい。サンプルサイズ1000となればかなり近い値となる。
サンプルサイズ 10
・母平均 = 50
・母分散 = 100
・母標準偏差 = 10
・母標準誤差 = 3.1623
------
・標本平均 = 49.029
・標本分散 = 141.82
・標本標準偏差 = 11.909
・標本標準誤差 = 3.766
------
・不偏分散 = 157.58
・不偏分散の平方根 = 12.553
・不偏標準誤差(不偏分散の平方根/√N) = 3.9697
サンプルサイズ 100
・母平均 = 50
・母分散 = 100
・母標準偏差 = 10
・母標準誤差 = 1.0
------
・標本平均 = 50.743
・標本分散 = 68.86
・標本標準偏差 = 8.2982
・標本標準誤差 = 0.82982
------
・不偏分散 = 69.556
・不偏分散の平方根 = 8.34
・不偏標準誤差(不偏分散の平方根/√N) = 0.834
サンプルサイズ 1000
・母平均 = 50
・母分散 = 100
・母標準偏差 = 10
・母標準誤差 = 0.31623
------
・標本平均 = 50.274
・標本分散 = 98.569
・標本標準偏差 = 9.9282
・標本標準誤差 = 0.31396
------
・不偏分散 = 98.668
・不偏分散の平方根 = 9.9332
・不偏標準誤差(不偏分散の平方根/√N) = 0.31411
サンプルサイズ 10000
・母平均 = 50
・母分散 = 100
・母標準偏差 = 10
・母標準誤差 = 0.1
------
・標本平均 = 50.075
・標本分散 = 100.2
・標本標準偏差 = 10.01
・標本標準誤差 = 0.1001
------
・不偏分散 = 100.21
・不偏分散の平方根 = 10.011
・不偏標準誤差(不偏分散の平方根/√N) = 0.10011
標本分布のプロット、および不偏分散の平方根と母標準偏差のズレ
母集団からサイズ10の標本抽出を10,000回繰り返すシミュレーションを行い、標本分布をプロットしてみる。更に、不偏分散の平方根は母標準偏差とどの程度ズレが生じるのかを確認して、参考サイトにある係数c4による補正を試してみる。
#平均50, 標準偏差10、分散100の正規分布を利用 loc = 50 scale = 10 population = stats.norm(loc = loc, scale = scale) sample_size = 10 n_trial = 10000 sample_mean_array = np.zeros(n_trial) sample_var_array = np.zeros(len(sample_mean_array)) sample_std_array = np.zeros(len(sample_mean_array)) np.random.seed(2) for i in range(0, n_trial): sample = population.rvs(size = sample_size) sample_mean_array[i] = sp.mean(sample) sample_var_array[i] = sp.var(sample, ddof=1) sample_std_array[i] = sp.std(sample, ddof=1) #標本平均のヒストグラムに、理論的な標本分布を重ね合わせて表示 sns.distplot(sample_mean_array, kde=False, norm_hist = True) x = np.arange(start = 40, stop = 60, step = 0.1) plt.plot(x, stats.norm.pdf(x=x, loc=loc, scale=scale/sp.sqrt(sample_size))) plt.xlabel("Sample mean") plt.ylabel("Frequency") #不偏分散の平方根から、不偏標準偏差(母標準偏差の不偏推定量)を求めるための補正係数 #※ただし、母集団が正規分布に従うことが前提 c4 = sp.sqrt(2/(sample_size-1))*gamma(sample_size/2)/gamma((sample_size-1)/2) #各統計量を表示 print(f'サンプルサイズ {sample_size}') print(f'・母平均 = {loc}') print(f'・母分散 = {scale ** 2}') print(f'・母標準偏差 = {scale}') print(f'・母標準誤差 = {scale/sp.sqrt(sample_size):.5}') print('--------') print(f'・標本平均の平均 = {sp.mean(sample_mean_array):.5}') print(f'・不偏分散の平均 = {sp.mean(sample_var_array):.5}') print(f'・不偏分散平方根の平均 = {sp.mean(sample_std_array):.5}') print(f'・不偏標準誤差の平均 = {sp.mean(sample_std_array/sp.sqrt(sample_size)):.5}') print('--------') print(f'・c4 = {c4:.5}') print(f'・不偏標準偏差(不偏分散平方根/c4) = {sp.mean(sp.sqrt(sample_var_array))/c4:.5}')
標本平均の平均、および不偏分散の平均はそれぞれ母数と非常に近い値となっている一方、不偏分散の平方根の平均は9.7366となり母標準偏差(10)よりも小さい。手許の教科書によると、このシミュレーション条件では不偏分散の平方根の理論値は約9.7266となるとのことであり、近い値が得られている。不偏分散の平方根は母標準偏差の不偏推定量ではないことが確認出来た。
そしてこれを係数c4で補正することで、値は10.01となり母標準偏差と非常に近い値となることが確認出来た。
サンプルサイズ 10
・母平均 = 50
・母分散 = 100
・母標準偏差 = 10
・母標準誤差 = 3.1623
--------
・標本平均の平均 = 49.967
・不偏分散の平均 = 100.22
・不偏分散平方根の平均 = 9.7366
・不偏標準誤差の平均 = 3.079
--------
・c4 = 0.97266
・不偏標準偏差(不偏分散平方根/c4) = 10.01
標本分布のプロット。標本平均のヒストグラムと理論的な標本分布がきちんと重なっている。

Core MLを用いた、iPhone での機械学習あれこれ(4)
iPhoneでの機械学習あれこれ(1)を執筆した時点では、PyTorchモデルを直接Core MLモデルに変換するツールはありませんでした。当時から「Core ML tools」という機械学習モデルの変換ツール(Pythonパッケージ)はあったのですが、PyTorchには対応していませんでした。
しかし、今年の7月末にリリースされたCore ML tools 4.0では、遂にPyTorchモデルを直接Core MLモデルに変換可能となったようです。
そこで、早速導入してトライしてみました。まだまだ情報も少なく色々手探りでしたが、何とかある程度方法が理解出来てきましたので、どこかで誰かの役に立つかもしれないと信じてメモしてみます。
Core ML tools 4.0の導入
Core ML toolsのインストールは通常、以下のコマンドで行うことが出来るようです。
$ pip install -U coremltools
ただし本記事執筆時点では、Core ML tools 4.0はまだbeta版としてのリリースなので、以下のように --pre をつける必要があるようです。
$ pip install -U --pre coremltools
インストールが完了したら、以下のようにpythonコードを実行すればバージョン確認が出来ます。
#本記事執筆時点では ”4.0b3” と表示 import coremltools as ct print(ct.__version__)
PyTorchモデルのCore MLモデルへの直接変換
入力がMLMultiArray型となるモデル
手始めにiPhoneでの機械学習あれこれ(1)で用いたMNISTの手書き数字分類モデルを、ONNXを介さず、直接Core MLモデル(入力はMLMultiArray型)に変換してみます。
#Pythonコード #過去記事(iPhoneでの機械学習あれこれ(1))で作成したMNISTの #手書き数字分類モデルを,直接Core MLモデルに変換する import torch import torchvision import torch.nn as nn import torch.optim as optim import torch.nn.functional as F import torchvision.transforms as transforms import coremltools as ct #モデルおよびパラメータについては過去記事参照 class MNIST_Conv_MN(nn.Module): def __init__(self): super(MNIST_Conv_MN, self).__init__() self.conv1 = nn.Conv2d(1, 8, 3) self.pooling = nn.MaxPool2d(2, 2) self.fc1 = nn.Linear(13 * 13 * 8, 10) def forward(self, x): x = self.conv1(x) x = F.relu(x) x = self.pooling(x) x = x.view(-1, 13 * 13 * 8) x = self.fc1(x) return x model = MNIST_Conv_MN() model.load_state_dict(torch.load('MNIST.pth')) #モデルへの入力データを用意するが,形状さえ合っていれば #rand関数などで生成したダミーデータで問題がない模様 #本モデルではMNIST画像(28 * 28 のグレースケール)をミニバッチの形に #したものが入力となるため,ダミーの形状は(1, 1, 28, 28) となる dummy_input = torch.rand(1, 1, 28, 28) #torch.jit.trace関数を用いて,モデルをTorchScriptという #中間形式に変換する必要がある.先程のダミーデータを用いればOK trace = torch.jit.trace(model, dummy_input) #本モデルは0〜9の数字の分類問題用なので, ラベルを用意する classifier_config=ct.ClassifierConfig([i for i in range(10)]) #Core MLモデルに変換する(先程変換した中間形式を与える必要がある) #inputsとしてTensorTypeを与えると、データの入力形状がMLMultiArrayとなる #TensorTypeのnameを”input”にすると、Xcode上でエラーが出るので(名前の衝突?)避ける mlmodel = ct.convert( trace, inputs=[ct.TensorType(name="input_1", shape=dummy_input.shape)], classifier_config=classifier_config ) mlmodel.save("MNIST.mlmodel")
※TorchScriptの詳しいことついては正直な所、まだあまり理解出来ておりません。ひとまず公式リファレンスを載せておきます。PyTorchで学習したモデルをC++などで利用したりすることも可能となるようです。
pytorch.org
ひとまず、これだけでCore MLモデルに変換出来ます。試しにXcodeに追加して確認してみると、入力の型が「MultiArray (Float32 1 x 1 x 28 x 28)」となっています。

このモデルを用いて、iPhoneでの機械学習あれこれ(1)で作成した手書き数字を予測するアプリを作り直してみます。と言っても、coreMLRequestの中身のみを微修正するだけです。
//swiftコード //過去記事(iPhoneでの機械学習あれこれ(1))で作成した手書き数字予測アプリの //coreMLRequestのみ,今回変換したモデルに合わせて一部修正 func coreMLRequest(image: UIImage){ let imgSize: Int = 28 let imageShape: CGSize = CGSize(width: imgSize, height: imgSize) let imagePixel = image.resize(to: imageShape).getPixelBuffer() //過去記事ではMLMultiArrayの形状は(1, 28, 28)であったが, 本モデルは(1, 1, 28, 28)なので修正する. let mlarray = try! MLMultiArray(shape: [1, 1, NSNumber(value: imgSize), NSNumber(value: imgSize)], dataType: MLMultiArrayDataType.float32 ) for i in 0..<imgSize*imgSize { mlarray[i] = imagePixel[i] as NSNumber } //本記事で直接変換したCore MLモデル("MNIST.mlmodel")をロード let MNISTModel = MNIST() //本モデルでは入力用の変数名は"input_1", 出力用の変数名は”_45" if let prediction = try? MNISTModel.prediction(input_1: mlarray) { print(prediction._45) if let first = (prediction._45.sorted{ $0.value > $1.value}).first{ self.predictLabel.text = "予測:\(Int(first.key))" } } }
試しに動かしてみると、このモデルでもきちんと手書き数字を予測することが出来ました。

入力がCVPixelBuffer型となるモデル(Visionで利用可能)
入力がMLMultiArray型だと扱いが不便なので、iPhone での機械学習あれこれ(2)で触れたように、入力をCVPixelBuffer型にしてVisionで利用可能なモデルに直接変換したい所ですが、それも簡単に出来てしまいます。
先程の変換用コードで、ct.convertのinputsにTensorTypeを与えましたが、以下のようにImageTypeに変更するだけです。
#pythonコード #先程の変換コードうち、ct.convertを以下のように書き換える mlmodel = ct.convert( trace, inputs=[ct.ImageType(name="input", shape=dummy_input.shape, scale=1/255)], classifier_config=classifier_config )
ただしImageTypeでは入力画像の前処理を行わせることが出来ます。例えばモデルにVisionから画像を入力させる場合、その画素値は通常0〜255となります。一方で本モデルはiPhoneでの機械学習あれこれ(1)でも触れた通り、画素値が0〜1に正規化されたMNIST画像で学習しています。そこで、scale=1/255とスケーリングの設定をしておくことで、入力画像の画素値も0〜1にすることが出来ます。
厄介なのは必要なスケーリングを忘れて、入力の画素値がモデルの想定とズレていたとしても、後々Xcodeでの利用時にはエラー無しでビルドが通ってしまいます。その場合、ただただ出力が全然想定通りにならない(本モデルの場合、手書き数字の予測が全然当たらない)…というバグを抱える可能性があります
(実際、iPhone での機械学習あれこれ(2)の自作モデルで「1」が「8」に予測されたりしたのは、そのせいかもしれません…)。
変換出来たCore MLモデルを先程同様にXcode上で確認してみると、確かに入力の型が「Image (Grayscale 28 x 28)」とVisionで利用可能な形式になっています。

あとはiPhone での機械学習あれこれ(2)で作成した、Visionを用いた手書き数字予測アプリで、モデル名さえ書き換えればそのまま用いることが出来ます。
//Swiftコード //過去記事(iPhone での機械学習あれこれ(2))のVisionを用いた //手書き数字予測アプリで,モデル名を適宜書き換えればOK guard let model = try? VNCoreMLModel(for: MNIST().model) else { //モデル名書き換え。ここでは"MNIST.mlmodel"からとする fatalError("Loading CoreML Model Failed") }
きちんとスケーリングしたことで、「1」が「8」と認識されやすくなるような挙動も解消しました。

なお補足ですが、ImageTypeには他にもbiasを設定することが出来ます。これはスケーリング後の画素値に、更に設定した値を加えるものです。例えば入力画像の画素値を-1〜1にしたい場合は、以下の例のようにまず画素値を0〜2にスケーリングした後、biasでそこから1を引けば(-1を加えれば)良いようです。
#pythonコード #カラー入力画像のRGB画素値(0〜255)を、-1〜1にしたい場合 ct.ImageType(shape=(1, 3, 28, 28), scale=2/255, bias=[-1,-1,-1])
以上、色々手探りでしたが、Core ML Tool 4.0を用いて基礎的なPyTorchモデル→Core MLモデルの直接変換をやってみることが出来ました。
なお、今回は既にPyTorchで学習済みのモデルを変換しましたが、Core MLでは未学習のモデルをiPhoneやiPad上でオンデバイス学習することも出来たりするようですので、今後も色々調べてトライして行きたいと思います。
M5Stackでデータロガーのような温度・湿度計を作ってみた
結構前のことですが、↓のようなアイテムを気紛れに購入しました。いわばM5Stack用の充電スタンドですが、DHT12の温度・湿度センサを内蔵しており、M5Stackに差し込むだけで、それらが測定可能となる中々面白いアイテムです。

…と言いつつ、長らく買ったまま放置してしまっていたのですが、何か活用してみようと思い至り、データロガーのような温度・湿度計を作ってみました。

DHT12から拾った温度・湿度の値を、以下の過去記事でも触れたスプライトのスクロール機能を用いて、リアルタイムにグラフとして描画しています(あくまで見た目がデータロガーっぽいだけで、データを別途記録する機能などは実装していないですが)。
chemicalfactory.hatenablog.com
思い描いたイメージに結構近いものが作れたと感じましたので、どこかで誰かの参考になるかもと願い、ソースコードを公開してみたいと思います。目盛りの描画位置などは試行錯誤で調整した値を用いているなど、あまり美しいコードではありませんが…。
こちらはM5StackのDHT12サンプルスケッチを下敷きにしているので、まずはこれを開きます。

そしてサンプルスケッチの「DHT12」タブのコードを、以下のものに書き換えればOKです。
#include <M5Stack.h> #include "DHT12.h" #include <Wire.h> DHT12 dht12; //W、Hは画面の幅,高さ。GW、GHはグラフ領域の幅、高さ。 #define W 320 #define H 240 #define GW 280 #define GH 180 //グラフはスプライトを用いて描画する。初期化 TFT_eSprite graph = TFT_eSprite(&M5.Lcd); void setup() { M5.begin(); Wire.begin(); M5.Lcd.fillScreen(TFT_BLACK); //グラフ用スプライトの生成。setScrollRect関数を使用しない場合、 //スプライト全体がスクロール対象となる graph.setColorDepth(8); graph.createSprite(GW, GH + 1); graph.fillSprite(TFT_BLACK); } void loop() { //DHT12から温度、湿度の値を取得。 float temp = dht12.readTemperature(); float humid = dht12.readHumidity(); //グラフ用スプライトの配置、1ピクセルずつスクロールさせていく graph.pushSprite((W - GW)/2 - 1, 15); graph.scroll(-1, 0); //目盛り線の描画(1ピクセルのスクロール → 1ピクセル描画、の繰り返しで線になる) //y軸方向に10分割する for(int y = 0; y <= GH; y += GH/10) graph.drawPixel(GW-1, y, TFT_DARKGREEN); //温度用の目盛り。室温を想定して範囲は-10〜40'Cとし、目盛り線と合うように調整。 M5.Lcd.setTextColor(TFT_YELLOW); M5.Lcd.setTextSize(1); M5.Lcd.setCursor(0, 0); M5.Lcd.printf("Temp"); char tempScale[6][4] = {" 40", " 30", " 20", " 10", " 0", "-10"}; for(int i = 0; i < 6; i++){ M5.Lcd.setCursor(0, 12 + i * GH/10 * 2); M5.Lcd.printf("%s", tempScale[i]); } //湿度用の目盛り。範囲は0〜100 %とし、目盛り線と合うように調整。 M5.Lcd.setTextColor(TFT_BLUE); M5.Lcd.setTextSize(1); M5.Lcd.setCursor(W - 30, 0); M5.Lcd.printf("Humid"); char humidScale[6][4] = {"100", "80", "60", "40", "20", "0"}; for(int i = 0; i < 6; i++){ M5.Lcd.setCursor(GW + (W - GW)/2 + 1, 12 + i * GH/10 * 2); M5.Lcd.printf("%s", humidScale[i]); } //温度のグラフを描画。温度が目盛り範囲(-10〜40'C)から外れる場合は //強引に範囲内に収める(そんな環境で使うことは無いだろうけれど) if(temp > 40.0) temp = 40.0; if(temp < -10.0) temp = -10.0; float tc = -18.0 * (temp - 40.0) / 5.0; //実値をグラフ上の座標に変換 graph.drawFastVLine(GW - 1, (int)tc, 2, TFT_YELLOW); //湿度のグラフを描画。こちらは目盛り範囲(0〜100 %)から外れることはないはず float hc = -9.0 * (humid - 100.0) / 5.0; //実値をグラフ上の座標に変換 graph.drawFastVLine(GW-1, (int)hc, 2, TFT_BLUE); //グラフの真下に温度、湿度の実値を文字表示する M5.Lcd.setTextColor(TFT_WHITE, TFT_BLACK); //背景色を設定して、直前の表示が残らないようにする M5.Lcd.setTextSize(2); M5.Lcd.setCursor((W - GW)/2 - 1, H - 38); M5.Lcd.printf("Temperature('C):%5.1f", temp); M5.Lcd.setCursor((W - GW)/2 - 1, H - 19); M5.Lcd.printf("Humidity(%%): %5.1f", humid); //湿度の数値のx座標が、温度の数値と並ぶように調節 delay(50); }
matplotlibを用いたグラフの書き方(備忘録)
色々とPythonを使ってデータ処理を行う機会が増える(かもしれない)ので、matplotlibを用いたグラフの書き方についていくつかメモします。個人的な備忘録の意味合いが強く、他記事と書き方が異なっており、説明なども少なめです。今後は予告なく内容を追加するかもしれません。
※環境はJupyter Notebookの想定です。
- 基本的なグラフ
- 凡例(legend)の調整
- axesを用いる方法
- グラフの表示範囲を変更する
- 複数のグラフを並べる(1)
- 複数のグラフを並べる(2)
- 複数のグラフを並べる(3)
- グラフを点線にする
- 散布図を描く
- 棒グラフを描く
- imshowによる2次元配列の描画
- 多次元配列を用いた、2変数関数のimshowによる描画
- 様々なカラーマップを用いてのimshowによる描画
- 3次元グラフ(サーフェス)を描く
- 3次元グラフ(ワイヤフレーム)を描く
- 3次元のバーを用いて、曲面を描く
- 【参考】公式による、様々なグラフの描画例
基本的なグラフ
%matplotlib inline import numpy as np import matplotlib.pyplot as plt x = np.linspace(-np.pi, np.pi, 100) y1 = np.sin(x) y2 = np.cos(x) plt.plot(x, y1, label="sin") plt.plot(x, y2, label="cos") plt.title("Graph") plt.xlabel("x", size=12) plt.ylabel("y", size=12) plt.legend() plt.show()

凡例(legend)の調整
legendは配置やフォントサイズを調整出来る。 bbox_to_anchorはアンカーポイントであり、左下が(0, 0)、右上が(1, 1)。 locでアンカーポイントに対する凡例の枠の位置を指定する。borderaxespadは凡例の枠に対して、余白をどの程度設けるかの設定。
locで可能な指定は以下の通りとなる。
‘best’, ‘upper right’, ‘upper left’, ‘lower left’, ‘lower right’, ‘right’,
‘center left’, ‘center right’, ‘lower center’, ‘upper center’, ‘center’
%matplotlib inline import numpy as np import matplotlib.pyplot as plt x = np.linspace(-np.pi, np.pi, 100) y1 = np.sin(x) y2 = np.cos(x) plt.title("Graph") plt.xlabel("x", size=12) plt.ylabel("y", size=12) plt.plot(x, y1, label="sin") plt.plot(x, y2, label="cos") plt.legend(bbox_to_anchor = (1.0, 1.0), loc = "upper right", borderaxespad=1, fontsize = 15) plt.show()

axesを用いる方法
%matplotlib inline import numpy as np import matplotlib.pyplot as plt x = np.linspace(-np.pi, np.pi, 100) y1 = np.sin(x) y2 = np.cos(x) fig = plt.figure(figsize=(5, 5)) ax = fig.add_subplot(111) ax.plot(x, y1, label="sin") ax.plot(x, y2, label="cos") ax.set_title("Graph") ax.set_xlabel("x", size=12) ax.set_ylabel("y", size=12) plt.legend(bbox_to_anchor = (0.0, 1.0), loc = "upper left", borderaxespad=1, fontsize = 12) plt.show()

グラフの表示範囲を変更する
plt.xlim(a, b), plt.ylim(a, b)を使用する(axesの場合はax.set_xlim(a, b)といった形にする)。
↓最初の「基本的なグラフ」に対して、plt.xlim(-1, 1), plt.ylim(-2, 2)を設定した場合。

複数のグラフを並べる(1)
%matplotlib inline import numpy as np import matplotlib.pyplot as plt fig, axes = plt.subplots(2, 2, figsize=(12, 6)) ax1, ax2, ax3, ax4 = axes.flatten() #以下のように1行で書くことも出来る #fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(12, 6)) #あるいは以下のように、1つ1つ追加することも出来る。subplotは(行数、列数、番号) #subplot(2, 2, 1)ではなくsubplot(221)のように書くことも可能 #fig = plt.figure(figsize=(12, 6)) #ax1 = fig.add_subplot(2, 2, 1) #ax2 = fig.add_subplot(2, 2, 2) #ax3 = fig.add_subplot(2, 2, 3) #ax4 = fig.add_subplot(2, 2, 4) x = np.linspace(-3*np.pi, 3*np.pi, 300) y0 = np.sin(x) y1 = np.cos(x) y2 = np.abs(np.sin(x)) y3 = np.abs(np.cos(x)) #凡例にLaTeXコマンドを使用する(raw文字列にする必要あり) ax1.plot(x, y0, color = "red", label = r"$\sin x$") ax2.plot(x, y1, color = "blue", label = r"$\cos x$") ax3.plot(x, y2, color = "green", label = r"$|\sin x$|") ax4.plot(x, y3, color = "yellow", label = r"$|\cos x$|") ax1.set_title("Graph 1") ax2.set_title("Graph 2") ax3.set_title("Graph 3") ax4.set_title("Graph 4") ax1.set_xlabel("x") ax2.set_xlabel("x") ax3.set_xlabel("x") ax4.set_xlabel("x") ax2.set_ylabel("y") ax2.set_ylabel("y") ax2.set_ylabel("y") ax2.set_ylabel("y") #locは指定しないと、各グラフで凡例の位置がバラける ax1.legend(loc = "upper right") ax2.legend(loc = "upper right") ax3.legend(loc = "upper right") ax4.legend(loc = "upper right") #並んだグラフのタイトルやラベルが、重なってしまうことを防ぐ fig.tight_layout() plt.show()

複数のグラフを並べる(2)
forループを用いて短く記述。出力されるグラフは(1)と同じ。
%matplotlib inline import numpy as np import matplotlib.pyplot as plt fig, axes = plt.subplots(2, 2, figsize=(12, 6)) faxes = axes.flatten() x = np.linspace(-3*np.pi, 3*np.pi, 300) y0 = np.sin(x) y1 = np.cos(x) y2 = np.abs(np.sin(x)) y3 = np.abs(np.cos(x)) y = [y0, y1, y2, y3] colorlist = ["red", "green", "blue", "yellow"] # 各プロットの色 labellist = [r"$\sin$",r"$\cos x$",r"$|\sin x|$",r"$|\cos x|$"] # 各ラベル for i, ax in enumerate(faxes): ax.plot(x, y[i], color=colorlist[i], label=labellist[i]) ax.set_title(f"Graph {i+1}") ax.set_xlabel("x") ax.set_ylabel("y") ax.legend(loc = "upper right") fig.tight_layout() plt.show()
複数のグラフを並べる(3)
グラフ1内に別のグラフ2を、任意の位置・サイズで描画する。left, bottomはグラフ2の左下位置、width, heightはグラフ2の幅、高さであり、それぞれグラフ1(figure)の範囲に対する相対値で指定する。
#グラフ1を上書きする形になるので、きちんと使うなら調整が必要。 %matplotlib inline import numpy as np import matplotlib.pyplot as plt x = np.linspace(-np.pi, np.pi, 100) y1 = np.sin(x) y2 = np.cos(x) plt.figure(figsize=(8, 5)) plt.plot(x, y1, label="sin") plt.legend(bbox_to_anchor = (0.0, 1.0), loc = "upper left", borderaxespad=1, fontsize = 12) ax2 = plt.axes([0.2, 0.2, 0.4, 0.4]) #[left, bottom, width, height] ax2.plot(x, y2, label="cos") plt.legend(bbox_to_anchor = (0.0, 1.0), loc = "upper left", borderaxespad=1, fontsize = 12) plt.show()

グラフを点線にする
plot()関数の、linestyle引数(lsと略記も可)で指定する。linewidth引数で線の太さも変更できる。 linestyleとして可能な指定は下表の通り。
※散布図(scatte)の場合、linewidthではマーカーの輪郭線の太さの指定となる。
| ":" | 点線 |
| "-." | 一点鎖線 |
| "--" | 破線 |
| "-" | 実線 |
import numpy as np import matplotlib.pyplot as plt %matplotlib inline fig, axes = plt.subplots(2, 2, figsize=(10, 6)) faxes = axes.flatten() x = np.linspace(-np.pi, np.pi, 100) y = np.sin(x) stylelist = [":", "-.", "--", "-"] for i, ax in enumerate(faxes): ax.plot(x, y, color = "blue", ls = stylelist[i], linewidth = 2) ax.set_title(f"linstyle \"{stylelist[i]}\"") fig.tight_layout() plt.show()

散布図を描く
%matplotlib inline import numpy as np import matplotlib.pyplot as plt x = np.linspace(-np.pi, np.pi, 50) y = np.sin(x) plt.plot(x, y, color=(0.2, 0.8, 0.2)) #ノイズを加える y += 0.2 * np.random.randn(len(x)) plt.scatter(x, y) plt.show()

棒グラフを描く
%matplotlib inline import numpy as np import matplotlib.pyplot as plt np.random.seed(0) x = [0, 1, 2, 3, 4] y = np.random.rand(5) label = ["A", "B", "C", "D", "E"] plt.bar(x=x, height=y, tick_label=label) plt.xlabel("Sample") plt.ylabel("Value") plt.show()

imshowによる2次元配列の描画
cmap引数でカラーマップを指定する。カラーマップの一覧は以下の公式リファレンスを参照。
https://matplotlib.org/examples/color/colormaps_reference.htmlmatplotlib.org
%matplotlib inline import numpy as np import matplotlib.pyplot as plt plt.imshow(np.random.randn(50, 50), cmap = "magma") plt.title("50 x 50”)

多次元配列を用いた、2変数関数のimshowによる描画
Numpyの関数であるmgridを使用して、格子状の多次元配列を手軽に生成出来る。
mgrid[(x始点) : (x終点) : (x刻み幅), (y始点) : (y終点) : (y刻み幅)] または
mgrid[(x始点) : (x終点) : (x分割数)j, (y始点) : (y終点) : (y分割数)j] という形で使用する。
刻み幅の所に”j”を付けると、始点〜終点の区間を何分割するかという指定に変わる。
%matplotlib inline import numpy as np import matplotlib.pyplot as plt #それぞれ-2〜2の区間を400分割する y, x = np.mgrid[-2:2:400j, -2:2:400j] z = 10*np.sin(x**2 + y**2) plt.imshow(z)

様々なカラーマップを用いてのimshowによる描画
先述のカラーマップ一覧のうち、いくつかをピックアップして、適用したグラフを並べてみる。
%matplotlib inline import numpy as np import matplotlib.pyplot as plt y, x = np.mgrid[-np.pi:np.pi:300j, -np.pi:np.pi:300j] z = 10 * np.cos(x**2 + y**2) fig, axes = plt.subplots(6, 4, figsize=(12, 18)) faxes = axes.flatten() #公式リファレンスのカラーマップ一覧よりピックアップ cmaplist = ["viridis", "plasma", "inferno", "magma", "Greys", "Reds", "GnBu", "YlOrBr", "bone", "spring", "winter", "hot", "PiYG", "PuOr", "RdYlBu", "coolwarm", "Pastel1", "Paired", "Set1", "tab20", "flag", "prism", "terrain", "gist_rainbow"] for i, ax in enumerate(faxes): ax.imshow(z, cmap = cmaplist[i]) ax.set_title(f"{i+1} : {cmaplist[i]}") fig.tight_layout() plt.show()

3次元グラフ(サーフェス)を描く
Numpyの関数であるmeshgridを使用して、別の方法で格子状の多次元配列を生成する。そしてAxes3Dモジュールを用いて、add_subplot()の引数でprojection=‘3d’と指定することで、3次元グラフを扱うことが可能となる。
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D %matplotlib inline x1 = np.linspace(0, 1, 100) x2 = np.linspace(0, 1, 100) x1, x2 = np.meshgrid(x1, x2) y = 0.3 * x1**2 + 0.7 * x2**2 fig = plt.figure(figsize=(10, 10)) ax = fig.add_subplot(111, projection="3d") #3次元版 ax.set_xlabel(r"$x_1$", fontsize=16) ax.set_ylabel(r"$x_2$", fontsize=16) ax.set_zlabel(r"$y$", fontsize=16) surf = ax.plot_surface(x1, x2, y, rstride=5, cstride=5, cmap="plasma", alpha=0.8) plt.colorbar(surf, ax=ax, shrink=0.75) plt.show()
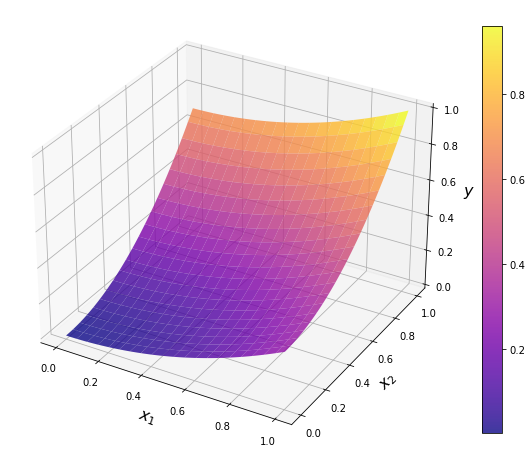
3次元グラフ(ワイヤフレーム)を描く
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D %matplotlib inline x1 = np.linspace(0, 1, 100) x2 = np.linspace(0, 1, 100) x1, x2 = np.meshgrid(x1, x2) y = 0.3 * x1**2 + 0.7 * x2**2 fig = plt.figure(figsize=(10, 10)) ax = fig.add_subplot(111, projection="3d") #3次元版 ax.set_xlabel(r"$x_1$", fontsize=16) ax.set_ylabel(r"$x_2$", fontsize=16) ax.set_zlabel(r"$y$", fontsize=16) ax.plot_wireframe(x1, x2, y, linewidth=0.5) plt.show()

3次元のバーを用いて、曲面を描く
bar3Dは本来、ヒストグラムや棒グラフを描くためのものであるが、これで強引に曲面を描いてみる。
bar3Dにおける各バーの座標は1次元配列で与える必要があるため、ravel関数で変換を行う。またバーの高さ(この場合はyの値)に応じて、カラーマップを割り当てるような仕組みは自前で実装する必要がある。
mport numpy as np import matplotlib.pyplot as plt import matplotlib.colors as colors import matplotlib.cm as cm %matplotlib inline x1 = np.linspace(0, 1, 20) x2 = np.linspace(0, 1, 20) x1, x2 = np.meshgrid(x1, x2) xr1 = x1.ravel() xr2 = x2.ravel() y = 0.3 * xr1**2 + 0.7 * xr2**2 def ColorMap(z, cmap): cmap = cm.get_cmap(cmap) norm = colors.Normalize(vmin = z.min(), vmax = z.max()) return cmap(norm(z)) fig = plt.figure(figsize=(10, 10)) ax = fig.add_subplot(111, projection='3d') ax.set_xlabel(r"$x_1$", fontsize=16) ax.set_ylabel(r"$x_2$", fontsize=16) ax.set_zlabel(r"$y$", fontsize=16) ax.bar3d(xr1, xr2, 0, 0.05, 0.05, y, color=ColorMap(y, 'plasma')) plt.show()
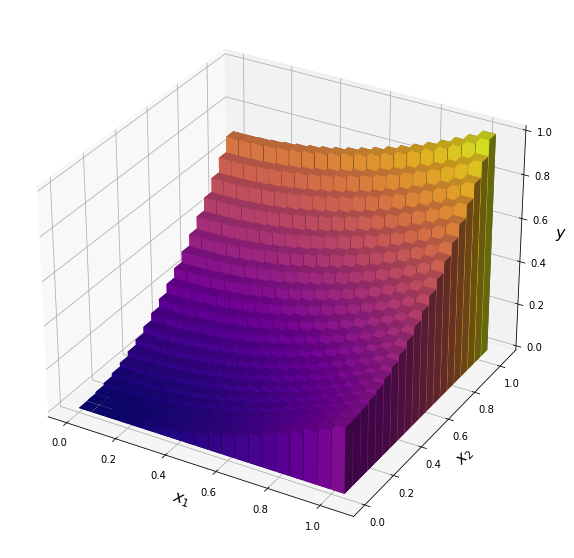
【参考】公式による、様々なグラフの描画例
Core MLを用いた、iPhone での機械学習あれこれ(3) Create ML編
前回記事の末尾で触れた通り、Create MLを使った機械学習についても試してみました。
Create ML上にテンプレートが用意されている機械学習(画像分類、オブジェクト検出、テキスト分類など)であれば、自分でコードを書いたりネットワークモデルを構築したりすることなく、画面操作だけでCore MLモデルファイル(.mlmodel)を作ることまで出来てしまい、非常にお手軽です。もちろんVisionでも利用可能です。
本記事では題材として、Create MLを活用して、iPhoneのカメラに映った「ラーメン」と「スパゲッティ」を見分けるアプリを作成してみます。目の前に麺料理が置かれているけれど、どちらか分からない、そんな良くあるシチュエーションで役立つかもしれません(0点)。
下準備:学習用の画像データ準備
Create MLに進む前に、まずは学習に用いる画像データを用意しておく必要があります。本記事の題材では、大量のラーメンとスパゲッティの画像を用意しなくてはなりません。
また、これらだけを学習させたモデルでは、何であっても無理矢理ラーメンかスパゲッティのどちらかに分類してしまいます。これを避けるために、ここでは「どちらでもない物」の画像、すなわち単なる風景や人物の写真も用意して一緒に学習させてみます。
ラーメンとスパゲッティについては、Google画像検索で出てくる画像を利用させて頂く方針とします。なお2019年1月より施行された著作権法の改正により、第三者が著作権を有する画像であっても、機械学習に限った利用(学習用データとしたり、それにより得られた学習済みモデルを公開したり)であれば合法的に行えるようになったようです。
ただし、画像を1つ1つ手作業でダウンロードしていたら大変ですので、ツールを使った方が良いと思います。ここでは私が試してみて便利だと感じた外部ツールを2つ紹介します(使用法などの詳細までは立ち入りませんが)。
- google-image-download
ここではラーメン、スパゲッティの画像をそれぞれ60枚用意します(50枚はトレーニング用、10枚はテスト用とする)。機械学習用としては枚数が少なく思えますが、Create MLではこの程度の量でも学習出来るのがウリとのことですので、これでやってみます。

なおCreate MLで用いる画像データの指針が公式のドキュメントに詳しく書かれています。重要そうな箇所をピックアップしてざっくり意訳すると以下のようになります。
- 各ラベル(分類)の画像はそれぞれ約80%をトレーニング用、20%をテスト用に回す。
- 各ラベルのトレーニング用画像は、それぞれ少なくとも10枚を用意する。
- 各ラベル毎の画像数はバランスを取る(本記事の例では、ラーメンの画像1000枚、スパゲッティの画像10枚のように偏るのはNG)
そして先述の通り、今回はラーメンとスパゲッティのどちらでもない物の画像を用意します。ここでは手許にあったCOCO データセット(2017)から、風景や人物が写った画像を60枚適当にピックアップして使用してみます。

そして下図のようにトレーニング用、テスト用の画像を格納するためのフォルダを作成し、それらの下には各画像のラベルとなる名前を付けたフォルダをそれぞれ作成します。ここではラーメンは”ramen”、スパゲッティは”spaghetti”、どちらでもない物は”other"フォルダとしました。これらの名前はそのままCreate MLに取り込まれ、出力されるCore MLモデルでも使用されるので注意が必要です。

後はそれぞれのフォルダに、集めた画像をトレーニング用とテスト用に分けて格納しておきます。
Create MLでラーメンとスパゲッティを分類するモデル作成
- いよいよCreate MLを実際に使ってみます。Xcode(本記事執筆時点:Version 11.4)メニューの「Open Developer Tool」から起動することが出来ます。

- 最初にファイル選択用のダイアログが表示されますので、新しく学習を行う場合は、左下の「New Document」を選択します。

- 実行したい機械学習のテンプレートを選択するダイアログが表示されます。本記事では画像分類を行いたいので「Image Classifier」を選択します。

- プロジェクト名を入力するダイアログが表示されますので、適当な名前を付けて保存します。ここでは「NoodleClassifier」という名前にしました(スパゲッティとラーメンにしか対応しませんが)。このプロジェクト名は、後々出力するモデルファイル名にも付与されます。

- プロジェクトを保存すると、Create MLのメイン画面が開きます。

- 「Training Data」の枠に、あらかじめ準備したトレーニング用画像を格納したフォルダを、ドラッグ&ドロップで投入します(下にある「Choose」の部分を操作することで、ダイアログからフォルダを選択することも出来ます)。

- 同様に「Testing Data」にも、テスト用画像を格納したフォルダを投入します。正常に行けば下図のようになります。今回トレーニング画像は60枚 x ラベル3種 = 180枚、テスト画像は10枚 x ラベル3種 = 30枚であり、正しい数が表示されています。「Validation Data」は自動選択(Auto)に任せることにします。

- 後はトレーニングの最大繰り返し回数(Maximum Iterations)やデータオーギュメンテーションの設定をします。これらについては公式ドキュメント(日本語)にも簡単な解説があります。回数を大きくしたり、オーギュメンテーションの設定を適用したりすることで、モデルの画像分類精度を向上できる可能性はありますが、もちろんそれだけ学習に時間が掛かるようになります。ここでは全く根拠はありませんが、下図の設定で学習を行ってみます。

- 後は画面上部の「Train」ボタンをクリックするだけで学習が始まります。下図のように進捗バーが表示されますので、終わるまで気長に待ちましょう。今回の学習は、私の環境(MacBook Air、13-inch、2018)で約30分でした。

- 学習後は下図のように結果が表示されます。今回はトレーニング用画像に対する精度は100%。テスト用画像に対する精度は97%となりました(同じ設定でも、実行するたびに乱数によって結果は微妙に異なってきます)。少ない画像数と適当な設定の割には中々のものです。

- 画面右上の「Output」にCore MLモデルが生成されていますので、フォルダに対してドラッグ&ドロップすれば取得出来ます。これにてCreate MLを用いた学習の手順が一通り完了しました。

iPhoneカメラに映ったラーメンとスパゲッティを見分ける
早速、生成したCore MLモデルを用いて、iPhoneカメラに映ったラーメンとスパゲッティを見分けるアプリを実装します。Xcodeで「Single View App」の新規プロジェクトを作成し、NoodleClassifierのCore MLモデルを追加しておきます。
そしてStoryboard上に、適当なサイズのUIView、UITextViewを配置します(下図の例では青い正方形がUIView、白い長方形がUITextViewです)。このView上にiPhoneカメラに映っているものを表示します。

後はAVFoundationを用いて、iPhoneカメラの映像をリアルタイムに取得し、フレーム毎に前記事と同様の手順で、Vision上でNoodlClassifierを用いた画像分類を行います。そこにラーメン or スパゲッティが映っているのを検出したら「ラーメン発見!」 or 「スパゲッティ発見!」とUITextViewに表示します。以下にコードを示します。
import UIKit import AVFoundation import CoreML import Vision class ViewController: UIViewController { //Storyboardに配置したUIView、UITextViewのアウトレット @IBOutlet weak var videoView: UIView! @IBOutlet weak var resultTextView: UITextView! override func viewDidLoad() { super.viewDidLoad() // Do any additional setup after loading the view. self.Capture() } func Capture(){ //AVCaptureSessionはデバイスからの入出力管理を担う let captureSession = AVCaptureSession() //画質の設定。ここでは高解像度の画像出力が可能な.photoを設定 captureSession.sessionPreset = .photo //入力の設定。ここではデバイスとしてビデオカメラを使用する。 //guard文で設定が正しく行われたか、複数判定を同時に実施。 guard let captureDevice = AVCaptureDevice.default(for: .video), let captureDeviceInput = try? AVCaptureDeviceInput(device: captureDevice), captureSession.canAddInput(captureDeviceInput) else { fatalError("Error: 入力デバイスの設定に失敗しました") } captureSession.addInput(captureDeviceInput) //出力の設定。 let videoDataOutput = AVCaptureVideoDataOutput() //AVCaptureVideoDataOutputSampleBufferDelegateプロトコルに適合する //デリゲート先を設定(ここではselfとして、viewController自身に設定) //デリゲート先で、フレーム毎にcaptureOutputメソッドが呼ばれるようになる videoDataOutput.setSampleBufferDelegate(self, queue: DispatchQueue(label: "VideoQueue")) guard captureSession.canAddOutput(videoDataOutput) else { fatalError("Error: 出力デバイスの設定に失敗しました") } captureSession.addOutput(videoDataOutput) // Storyboardに配置したUIView上に、プレビューを表示するように設定する。 let previewLayer = AVCaptureVideoPreviewLayer(session: captureSession) previewLayer.videoGravity = .resizeAspectFill previewLayer.frame = self.videoView.bounds self.videoView.layer.insertSublayer(previewLayer, at: 0) // キャプチャ開始 captureSession.startRunning() } } //setSampleBufferDelegateで設定した通り、AVCapture〜Delegateプロトコルを指定 //フレーム毎に呼ばれるcaputeOutputメソッドを実装し、ここでCore MLによる //画像判定の処理を行う extension ViewController: AVCaptureVideoDataOutputSampleBufferDelegate { func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) { //CMSampleBufferをCVPixelBufferに変換し、Core MLの入力と出来るようにする //(返り値はCVImageBufferとなっており、CVPixelBufferは元々そのタイプエイリアス) guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else { fatalError("Error: バッファの変換に失敗しました") } // NoodleClassifierのモデルをVisionで利用出来るようにロード guard let model = try? VNCoreMLModel(for: NoodleClassifier().model) else { fatalError("Error: Core MLモデルのロードに失敗しました") } // Core MLモデルを用いた画像認識リクエストを作成 let request = VNCoreMLRequest(model: model) { [weak self] (request: VNRequest, error: Error?) in guard let results = request.results as? [VNClassificationObservation] else { return } var text : String = "" //ラーメン or スパゲッティのconfidenceが0.8を超えた場合は、それを検出したと見做す。 if let result = results.first{ if result.identifier == "ramen" && result.confidence > 0.8{ text = "ラーメン発見!" }else if result.identifier == "spaghetti" && result.confidence > 0.8{ text = "スパゲッティ発見!" } } DispatchQueue.main.async { self?.resultTextView.text = text } } request.imageCropAndScaleOption = .centerCrop //リクエストを処理するためのハンドラ. let handler = VNImageRequestHandler(cvPixelBuffer: pixelBuffer) do{ try handler.perform([request]) } catch { fatalError("Error: 画像認識リクエストの処理に失敗しました") } } }
※本コードの実装においては、以下のサイトを参考にさせて頂きました。
iOS11のVision.frameworkを使ってみる - Qiita
Swiftでカメラアプリを作成する(1) - Qiita
AVCaptureVideoDataOutputの使い方 - Qiita
iPhoneの実機で早速アプリを試してみます。最初にごはんの類を映してみましたが何の反応も示しません。これを麺類と言い張られても困るのでOKですね。

一方でラーメンの類を映してみたところ、きちんと発見してくれました。このようなパッケージ写真であっても正しく検出出来るようです。

スパゲッティの類は手許に無かったので、某ファミレスのオンラインメニューを映してみました。カメラが遠いと、表示がラーメンとスパゲッティの間で激しくブレたりしますが、このぐらい近づけるとスパゲッティで安定しました。

アプリが判断に迷いそうなネタとして、スープスパゲッティも試してみました(写真はcookpadより)。色が濃い目のスープたっぷりであり、カメラが少し動くと表示が激しくブレたりしますが、カメラをあまり動かないようにすると、スパゲッティで安定しました(これは意外でした)。

というわけで、無事にラーメンとスパゲッティを見分けるアプリが完成しました(実際のところ、蕎麦やうどんなど他の麺類もラーメンかスパゲッティ認定されるなど、改良の余地は多々ありますが…)。
PyTorchやTensorFlowなどでモデルや学習のコードを自力実装する手間と比べると、恐ろしい程お手軽に機械学習を活用したアプリが作れてしまいました。Create MLでは学習の中身はブラックボックスであり(おそらく転移学習の一種?)、現時点ではやれることの種類も限られておりますが、それでも今後の開発の幅を広げてくれそうなツールだと感じます。
SpriteKitでビットマップフォント(2、BMGlyph版)
昔の記事では「Glyph Designer」というソフトウェアを用いてビットマップフォントを作成し、それをSpriteKitで使用する方法についてメモしました。
chemicalfactory.hatenablog.com
しかしながら、当時はGlyph Desingerは買い切り型のソフトウェアだったのですが、現在では月額制となってしまったようです(本記事作成時点では月¥900から、数ヶ月や年単位契約によるディスカウントもあるようですが)。趣味で細々とアプリ開発を嗜む身としては、ビットマップフォントの作成頻度がそこまである訳でもなく、少々重い金額です。
そこで代替となるソフトウェアを探していたのですが、良さげなものとして「BMGlyph」を見つけましたので、現在はこちらを使用しております。

本記事作成時点では¥1,220の買い切り型であり、日本語フォント対応、グラデーションやテクスチャによる文字の装飾、プレビューなど機能はかなり充実しており、イメージした通りのビットマップフォントが比較的容易に作成出来ると感じました(先日リメイクが完了して再リリースした「門清ドリルi」は、BMGlyphで作成したビットマップフォントを活用しています)。
操作法も比較的直感的で分かりやすく、公式ヘルプ(英語)内容の日本語訳を作成した素晴らしい外部サイトもあります。
mmorley.hatenablog.com
ただし上記サイトで解説されているフォントファイルの出力法はCocos2d向けとなっております。BMGlyphはSpriteKit向けのフォントファイルを出力する機能も備えていますが、公式サイトによるとSpriteKitでそれを扱うためには、以下のGitHubで公開されている「BMGlyphLabel」という専用のクラスを導入する必要があります。自分で試した限りでは、昔の記事のようにSKLabelNodeで扱うことは出来ないようです。
github.com
BMGlyphからSpriteKit向けに出力したフォントファイルを、BMGlyphLabelを用いて扱う方法に言及した日本語記事はほとんど無いようですので、どこかで誰かの役に立つかもしれないと信じて、本記事にメモしてみます。
SpriteKit向けフォントファイルの作成
まずはBMGlyphでお好みのビットマップフォントを作成します。ここでは例として、デフォルトのアルファベット・数字・記号に加えて、ひらがな、カタカナのテキストに対応したものにしてみました。そしてフォントはヒラギノ明朝 ProN W3としました。後ほど同フォントを設定した標準的なSKLabelNodeと比較してみたいと思います。
そしてフォントサイズは 24 にしようと思いますが、本記事執筆時点において現役のiPhone/iPad機種は、ほぼRetinaディスプレイ対応であり、画面スケールは2倍(@2x、iPhone 8や11など)または3倍(@3x、iPhone Xや11 Proなど)のいずれかとなります。@2xの機種の画面上で、フォントサイズが24に見えるよう表示するためには、サイズ48のフォントファイルを用意する必要があります。@3xの機種ならサイズ72 が必要です。そこで、ここではフォントサイズ(Font Size欄)を72に設定しておきます。

ビットマップフォントの編集が終わったら、BMGlyphの画面上方にある「Publish」をクリックして、フォントファイルの出力設定画面を呼び出します。最初はここで何をすれば良いのか分からず戸惑いましたが、こちらでは@2x向け、@3x向けなどと複数の出力設定を作成しておくことで、一括でそれらに対応したフォントファイルを出力することが出来ることが分かりました。

実例を示します。「Targets」欄で「+」を押すことで新しい出力設定を作成出来ます。また「duplicate」では既存の出力設定を複製出来ます。ここでは@2x向け、@3x向けの2種類を作成して、それぞれの内容を編集します。


- Directory Path:フォントファイルの出力先となるフォルダを指定します。各出力設定では全て揃えておいた方が無難と思います。
- File Name:フォントファイルの名前です。本例では「BMSample」としています。こちらも全て揃えておいた方が無難です。
- Suffix:重要項目であり、こちらで「@2x」「@3x」などの対象を区別します。
- Force Font Face:強制的にフォントの書体名を与えることが出来るようですが、通常は空白で構わないようです。
- Scale:出力設定ごとに、フォントファイルのスケールを変更するための重要項目です。今回は元々のフォントを72に設定しているので、@3x向けの設定では100%(スケール変更なし)、@2x向けの設定では66%(@3xの2/3、すなわちFont Size 48相当)とすることで、いずれの画面スケールの機種でも、画面上ではフォントサイズ24に見えるよう表示されます。
- Scale Quality:通常はデフォルトで問題ないようです。
- Format:こちらは忘れずに、全ての設定項目で「SpriteKit」に変更しておきます。
また、チェックボックスの項目のうち「Redraw when downscaling」は今回のように、設定項目によってフォントファイルのスケールを縮小する場合はチェックを入れておいた方が良いようです。全ての設定が終わったら「PUBLISH!」ボタンを押すと、問題が無ければSuffixごとのXMLファイル、および「〜.atras」のフォント画像が格納されたフォルダが生成されます。

これらのファイルは全て、ビットマップフォントを使用したいプロジェクトに、ドラッグ&ドロップなどで追加しておきます。
BMGlyphLabelの利用準備
BMGlyphLabelを利用可能とするために、まずは先述のGitHubより必要なファイルをダウンロードしておきます。なお、こちらはObjective-C版となります。Swift版もあるようですが、本記事執筆時点ではバージョンがSwift 3のものしか無いようですので、Swift 5であればObjective-C版を用いた方が、互換性の問題が生じづらいと思います。

ダウンロード&解凍した「BMGlyphLabel-master」フォルダ内に、「BMGlyphLabel」フォルダがあり、この中に必要なObjective-Cのソースおよびヘッダファイル計4つが入っています。これらをプロジェクトにドラッグ&ドロップで追加します。


このときブリッジングヘッダを作成するか確認するダイアログが表示されますので、作成しておきます。ブリッジングヘッダについては以下の過去記事を参照ください。

※ブリッジングヘッダについての参考記事
chemicalfactory.hatenablog.com
もちろんブリッジングヘッダでは、追加したヘッダファイル2つをインポートしておきます。これで必要な下準備は完了です。
#include "BMGlyphLabel.h" #include "BMGlyphFont.h"
BMGlyphLabelで、ビットマップフォントを表示する
下準備が整ったので、実際にBMGlyphLabelを用いて、SpriteKitでビットマップフォントを表示してみます。
//GameSceneは、SpriteKitのテンプレート(本記事執筆時点ではXcode 11.3) //を書き換えたものとする。シーンのAnchor Pointは(x, y) = (0.5, 0.5)想定 import SpriteKit class GameScene: SKScene { override func didMove(to view: SKView) { //BMGlyphから出力したフォントファイル名を指定して、フォントを作成 let BMSampleFont = BMGlyphFont(name: "BMSample") //BMGlyphLabelはSKNodeのサブクラスであり、他のノードと大体同様の //使い方が可能。ただしAnchor Pointの指定は出来ず、替わりにアラインメントで //左右や上下の揃え位置を指定する if let label = BMGlyphLabel(text: "BMGlyphのテスト", font: BMSampleFont){ label.position = CGPoint(x: 0, y: -20) label.horizontalAlignment = BMGlyphHorizontalAlignmentCentered label.verticalAlignment = BMGlyphVerticalAlignmentMiddle label.xScale = 1.0 label.yScale = 1.0 self.addChild(label) } //比較のために、SKLabelNodeを用いて、同じフォント、サイズで同じ文字を描いてみる let label2 = SKLabelNode(text: "BMGlyphのテスト") label2.fontName = "HiraMinProN-W3" label2.fontSize = 24 label2.position = CGPoint(x: 0, y: 20) self.addChild(label2) } }
試しに、画面スケールの異なる2機種のシミュレータで動かしてみました。それぞれに応じたスケールのフォントが自動的に使い分けられ、きちんと同様の表示が得られています。
iPhone 8 シミュレータ(@2x)

iPhone 11 シミュレータ(@3x)

xScale、yScaleを変更すれば、フォントサイズを調整することも出来ます。ただし、拡大の場合はやり過ぎると表示が粗くなるので、最初からサイズを大きくしたフォントファイルを用意した方が良いと思います。
if let label = BMGlyphLabel(text: "BMGlyphのテスト", font: BMSampleFont){ label.position = CGPoint(x: 0, y: -30) label.horizontalAlignment = BMGlyphHorizontalAlignmentCentered label.verticalAlignment = BMGlyphVerticalAlignmentMiddle label.xScale = 3.0 label.yScale = 3.0 self.addChild(label) } let label2 = SKLabelNode(text: "BMGlyphのテスト") label2.fontName = "HiraMinProN-W3" label2.fontSize = 72 label2.position = CGPoint(x: 0, y: 30) self.addChild(label2)
